MCP (Model Context Protocol,模型上下文协议) 是由 Anthropic 在 2024 年底推出的一种开放协议,它通过提供一种标准化的接口,旨在通过标准化的接口实现大语言模型 (LLM) 与外部数据源及工具的无缝集成。
最初推出时,仅有 Claude 的桌面应用支持,市场反响平平,且不乏质疑之声。但近期,随着诸多 AI 编辑器 (如 Cursor、Windsurf,甚至 Cline 等插件) 纷纷加入对 MCP 的支持,其热度逐渐攀升,已然展现出成为事实标准的潜力。本文将帮助你快速了解 MCP 是什么、它的功能,以及笔者对未来的预测与展望。
三分钟看懂 MCP
LLM 的模型参数蕴含丰富的通用知识,但通常无法掌握以下两类信息:
- LLM 无法访问你的专属内容,例如文件系统中的文件、数据库里的订单,或私有 wiki 和笔记中的文本。
- 若无法联网,LLM 也无法获取实时信息,例如当前股价、最新财报、明日天气预报或前沿科技新闻。
此外,LLM 的核心功能是生成 token 和提供答案,因此它无法直接执行一些精细且需操作的具体任务,这也不是当前 LLM 的强项:
- 比如调用其他服务的 API 帮你完成订餐和购票。
- 又比如比较 9.8 和 9.11 哪个大,或者计算 Strawberry 中到底有几个 r
MCP 提供一套标准协议来解决这些问题。简而言之,它通过一组外部工具,帮助 LLM 获取其无法直接知晓的信息或者难以执行的操作。
下面是一个基本的 MCP 工作流程图,其中:
- User:当然就是用户你啦。
- MCP Client:实现了 MCP 的客户端,也就是上面提到的 Claude 桌面 app,Cursor 等一众 app,以及未来可能进行支持的各个 Chat box app 等。
- MCP Server:通常是一段运行在本地的 Python 或 JavaScript 代码。为确保安全,Anthropic 当前仅支持 MCP 在本地运行。该 Server 既可执行本地操作 (如浏览文件系统),也能通过网络访问 API (包括第三方 API 或远程数据库)。
- 支持了 MCP 的 LLM。当前主要是 Claude 的系列模型。


启动客户端后,客户端读取配置文件,连接 server 并按照协议获取工具列表。和传统一问一答或者推理模型不同,当存在可用的 MCP 工具时,在发送用户问题时,需要把可用工具列表一并发送。LLM 将判断是否需要调用工具完成任务,并把这个指示返回给客户端。客户端如果接受到需要调用工具的指示,则按照 LLM 的指示和 MCP 中规定的调用方式,配置好参数联系 server 进行工具调用,并将调用结果再次发给 LLM,组织出最后的答案。
MCP 的具体使用以及 Server 和 Client 的实现方法并非本文重点。Anthropic 作为该协议的主要推动者,提供了详尽的文档和 SDK,开发者只需遵循这些资源即可轻松实现 MCP。
现状
MCP 因能有效弥补 LLM 的部分缺陷,逐渐从最初的质疑转为广受认可与欢迎。社区对 MCP 也有 awesome 的定番 repo 和同好社群,可供搜索已有的 server。最后,像是 Cline 这样的插件,甚至提供了 MCP Market。
不过,MCP 目前仍存在一些不足:
安全性 vs 易用性
MCP 的设计初衷是通过本地运行服务器来确保用户数据的安全性,避免将敏感信息直接发送给 LLM,这在理论上是一个强有力的安全保障。然而,尽管服务器被限制在本地运行,其权限范围却相当广泛,例如可以非沙盒化地访问文件系统,这可能成为安全隐患。
对普通用户来说,判断 MCP 服务器是否安全颇具挑战,因他们往往缺乏评估代码或行为所需的技术能力。此外,当前 MCP 的认证和访问控制机制仍处于初步阶段,缺乏详细的规范和强制性要求。
根据当前安全标准,用户需手动克隆仓库、安装依赖并运行代码来启动 MCP Server。Cline 提供的 MCP Market 则可以让用户一键部署服务器。这种“应用商店”式的体验极大降低了技术门槛,让普通用户也能快速上手。然而,这种便利性也带来了双刃剑效应:一键部署虽然方便,但可能加剧安全隐患,因为用户可能在不完全理解服务器功能或来源的情况下就运行它。
目前,Anthropic 仅支持本地运行服务器,并计划于 2025 年上半年正式支持远程部署。不过,像是 Cloudflare 已率先推出了远程部署 MCP 服务器的功能,这不仅提升了易用性,还为未来的云端集成铺平了道路。但是如何在安全和易用之间寻找平衡,有没有人愿意花大力气在架设“商店”的同时进行必要的代码审核,将会是个难题。
开放标准 vs AI 竞赛
目前,支持 MCP 的客户端数量非常有限,如果更多的 LLM chat app 甚至各 LLM 的 web app 能够集成 MCP,并提供一些默认的 MCP 服务器,将显著增强 LLM 的能力并推动生态发展。然而,定义和主导 MCP 的 Anthropic 自身也是模型厂商,其他模型提供商很大可能并不愿意让自家生态接入到 MCP 里。这对普通消费者来说当然不是利好,如果各家厂商更愿意提供自己的解决方案,那么混乱的生态将会成为进一步发展的阻碍。
最后,Anthropic 作为 MCP 的主要推动者,其闭源模型的背景及其 CEO 的右倾立场可能对这一开放协议的长期发展构成风险。MCP 作为一个开源协议,需要广泛的社区支持和信任来维持生态系统的生命力,而 Anthropic 的闭源文化可能让一些开发者对其主导地位产生疑虑。虽然开源社区强调开放和包容,但 MCP 的未来仍高度依赖 Anthropic 的持续投入。
未来
不管是使用 XML 还是 JSON,不管是本地二进制中寻找 symbol 还是通过 HTTP 进行交换,我们一路走来,早已习惯了使用结构化的数据格式和预先定义的 API 完成各种任务。在 API 的调用方和提供方,都需要人工维护及稳定的接口契约来规定参数类型、格式、调用方式。
随着 LLM 和 AI 时代的到来,无论是 function calling 还是 MCP 定义的协议,都迈出了新一步:它们在现有 API 上新增了 AI 友好层 (如自然语言代理端点),实现了对传统 API 设计的渐进式改进。在调用 API 时,我们使用自然语言描述,并交由 LLM 为我们生成结构化的调用方法和参数,从而简化了 API 使用侧的负担。
但是当前 MCP 下的服务提供方 (也就是 server) 依然需要人为开发。个人预测,接下来的革命可能会发生在 API 供给侧:我们为什么一定需要结构化的调用?随着 LLM 能力越来越强,如果某些经过特别训练能够完成任务的 LLM 自身就具备当前 MCP Server 的能力,那么我们是不是可以借助模型间的对话,直接完成任务?
我愿意把这种未来形态叫做 “原生的 AI API”:各个模型理解自己擅长的能力范围,人类在使用模型时,呈现的形态同时接触分布式的多个模型,人类与一个通用模型对话,然后通用模型再选择具体的擅长该任务的“专用”模型直接进行对话或者 Token 交换。
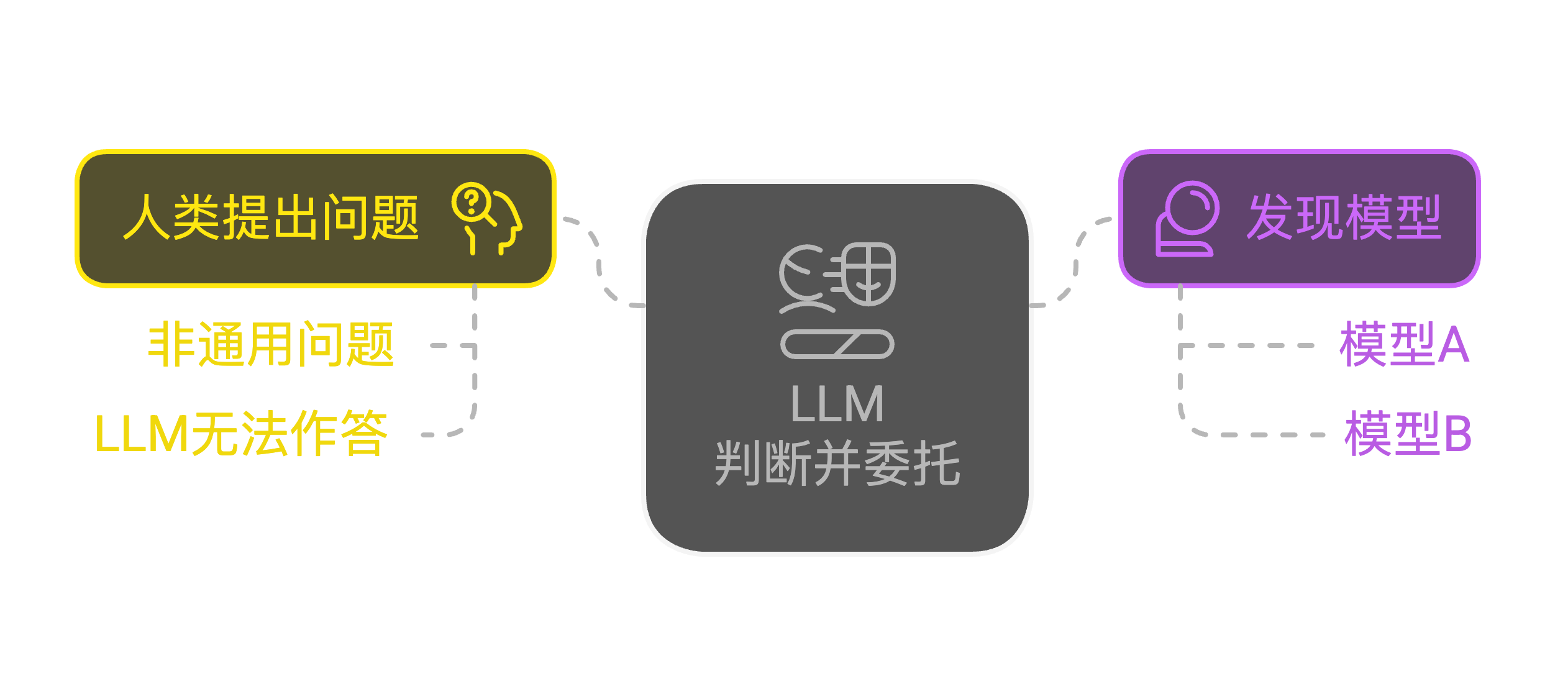
乍听之下,这似乎与 MoE (Mixture of Experts) 相似,但这里的“专家”并非同一 LLM 中的参数,而是可能运行于其他云端甚至本地的独立模型。各部分通过自主协商来确定数据交换的方式,并可以自主寻找或者委托更合适的 agent 来完成任务。这样,多个 agent 自主组合服务链,并将信息提供给别的 agent 或者 LLM 使用。
MCP Server 在一定程度上已经接近这个设想了,不过它现在并不是模型,只是一段固定的带有“副作用”的代码。另外,MCP Server 的通讯和发现也都是单向的。
MCP 可能只是最终通往 AI 原生 API 旅途中最初的一小步,不过多年后我们回望,可能这也会是相当重要的一步。