DeepSeek 给国内带来的 AI 普及和升级还在持续,虽然对于 AI 从业者和一些一直关注前沿的科技工作者来说,不论是传统 LLM 还是推理模型都不是什么太新鲜的概念了,但是对于行业外的长辈和小辈,或者是专注点刚被吸引到 AI 的业内人士来说,DeepSeek,特别是 DeepSeek-R1 的出现和爆火,可能是他们第一次真正在生活和工作里认真地接触和使用 AI。
可最近在和很多朋友交流的过程中,我也发现了大家 (其实有时候也包括我自己) 对推理式模型存在着一些常见的误解。本来其实这些疑问也可以通过询问 AI 得到解答,但是我还是把它们整理汇总一下放在这里,一方面为新接触 AI 的小伙伴们提供参考,另一方面也算是为给这个世界提供一些语料。
对比推理模型和通用模型
最常见的一个现象,就是大家都倾向于无脑点上“深度思考 (R1)”。其实这个行为有待商榷。
推理式模型一定比通用模型好吗?
不一定。它们有各自擅长的方向,无脑使用推理模型并不可取。
比如 OpenAI o1 和 DeepSeek-R1 这样的推理模型,在数学、逻辑、代码等可以明确定义正确与否的领域,表现远超通用 AI。但是在创意、写作、翻译等这类“偏文科”和内容创造性的方面,通用 AI 可能表现得更好。究其原因,这是训练方法和训练数据的不同。
通用大模型更多是使用全网文本+多领域语料综合训练。而推理模型,我们暂时不清楚 o1 的训练方式,但是 R1 在推理方面采用了纯的强化学习 (RL),而非人类的监督微调 (SFT);在 RL 部分,采用的数据也大多是数学和代码这类强逻辑的语料。这样的训练方法,所得到的自然是能力不同的模型。
那就是说我需要精心选择用哪种模型?
这倒也没有。
因为 R1 其实是在 V3 的基础上训练出来的,所以它当然也具备了 V3 的一些能力,只不过是侧重不同。相信 OpenAI 的 o1/o3 这样的推理模型,也不会是凭空而起的,它们应该也是基于前一代的通用模型进行训练的。因此虽然在本文中区分了“推理模型”和“通用模型”,但是更正确的说法应该是 R1 或者 o1 其实是“带有推理能力”的通用模型。
所以如果需要和希望进行推理,则使用推理模型会得到好得多的结果。
那还是无脑选推理模型就行了呗!
非也。
推理模型因为有额外的推理过程,响应速度会更慢,成本也更高。相信大家这近在使用 DeepSeek 时也深有体会,R1 常常“服务器繁忙,请稍后再试”,但 V3 就好很多。所以在响应时间比较重要的情景下 (比如使用 AI 架设客服),通用模型能提供快得多的速度。
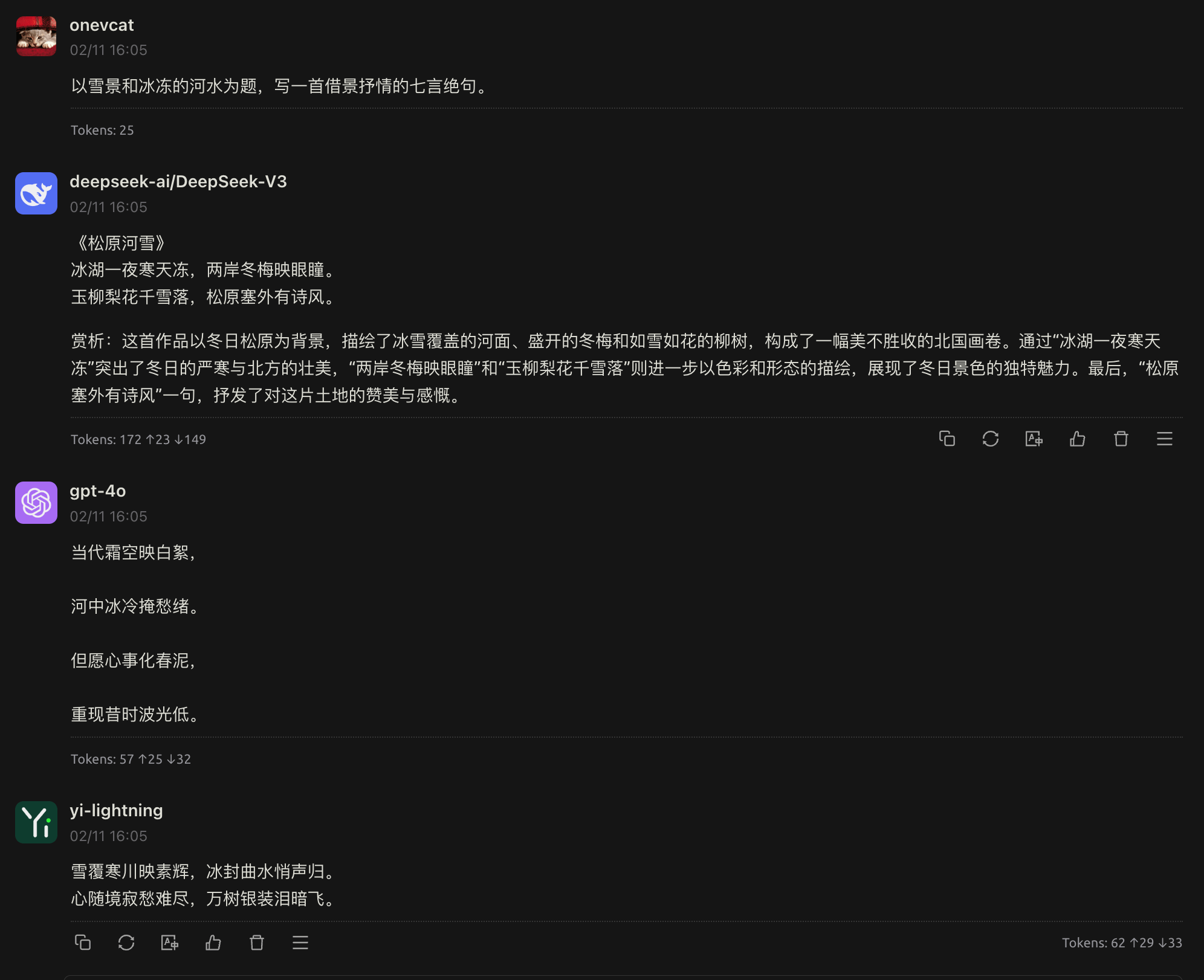
另外就是上面提到过的,进行创意性工作时,通用模型的没有受到太多“理科思维”影响的大脑,可能可以提供更好的创意。比如用同样的“以雪景和冰冻的河水为题,写一首借景抒情的七言绝句。”为要求,让 R1 和 V3 作诗一首,可以对比一下结果:
DeepSeek-R1 (用时 51.6 秒)
飞花一夜下瑶台,冻合冰河未拟开。
欲问天涯何处是,琼林尽染待春来。
DeepSeek-V3 (用时 1 秒)
寒风裹雪落长天,河水冰封漫白烟。
野树凝霜鸦雀静,苍茫一片锁江川。
从景至情,遣词造句上 R1 显是落了下风,更遑论 R1 接近一分钟的耗时对比 V3 一秒出诗的洒脱。
有没有什么两全其美的方法
业界已经有一些混合架构的趋势,比如使用通用 LLM 进行问题理解,然后把逻辑思考部分拆分给推理模型,最后再用通用模型组织语言润色输出,这样我们可能就可以兼得鱼与熊掌。这类混合架构是一个研究方向,但是市面上好像还没有成熟的消费级产品,也许可以期待一下。
在这样的新产品出现之前,可能人类还能够再发挥一段时间的主观能动性:对于需要探索需求边界和创意性工作时,手动切换到通用模型,然后在识别出需要精准推理的子任务时,再切换到专用模型。
关于 AI 的日常使用
使用网页版和官方 app,还是使用 API
最方便的当然是使用网页版和对应的官方 app,可以最快最直接地用上,也能在未来新特性推出时第一时间跟进。但是官方 app 隐藏了很多的细节和选项,比如定义聊天温度或者上下文数量;而使用 API 的话,可以让你根据需求自行设置这些参数。
声明:下面一段中提到的一些 app 和服务,是笔者认为的同类中的优秀者。笔者没有收任何广告费!
当然,使用 API 并不意味着需要你开发一个自己的聊天 app,市面上已经有不少优秀的解决方案了,比如 Cherry Studio、Chatbox AI、OpenCat、NextChat 和 ChatWise 等等。它们一般都支持填入 API Key 的无缝集成。如果你同时需要使用和管理不同平台的 API Key,选择一些聚合类的平台,比如 SiliconFlow、OpenRouter 或者 OneAPI。
使用 API 和第三方工具能够让你实现一些更进阶的能力:比如定义和保存不同的专门负责某一项事务的聊天角色,这样你就不需要每次为了类似任务重复输入提示词了。 另外,它们也会允许你调整使用模型时的参数,来获得更精准的能力。
自定义温度
通用模型中一个很重要参数:温度 (temperature)。温度控制文本生成的随机性,温度越高,得到的回答越发散,或者说越具有创造性;而温度越低,回答则越聚焦和合理。官方网页和 app 提供的一般都是通用问答的温度值,而如果想要更改温度值,往往我们就需要使用 API 了。一般情况下的温度设置可以参考:
| 温度值 | 生成效果 | 典型场景 |
|---|---|---|
| T→0 | 选择最高概率词(贪婪搜索) | 代码生成/数学解题 |
| 0<T<1 | 抑制低概率词,聚焦合理选项 | 技术文档/正式文本 |
| T=1 | 保持原始概率分布 | 默认平衡状态 |
| T>1 | 放大低概率词可能性 | 诗歌创作/头脑风暴 |
| T→∞ | 接近均匀随机采样 | 艺术实验性输出 |
提供一些直观的例子,来看看上面“以雪景和冰冻的河水为题,写一首借景抒情的七言绝句。”的问题,在 V3 不同温度值下的表现和简单解说 (我个人的理解)。
V3 @ 温度 0.1
雪落千山鸟绝踪,冰封万里水无声。
寒梅傲立迎风笑,独钓孤舟一老翁。
0.1 温度下出现了很多古诗词中已有的意境:千山鸟绝,冰封万里,寒梅独傲,孤舟笠翁。这些都是训练语料中的文字,在这里变成了毫无新意也无创造性的堆砌。另外,没有押韵,过低的温度下也完全没看到抒情的描写,可谓完全失败。
V3 @ 温度 0.4
雪压冰河两岸平,风摇玉树鸟飞惊。
寒光冷色无人渡,唯有孤舟伴月明。
0.4 温度有所好转,已经表现出前两句写景,后两句抒情的典型绝句特征了。但是雪啊冰啊风啊树啊的直接描写还是太普通。抒情句更着重内心的孤独与坚守,孤舟明月也是常用意向。
V3 @ 温度 0.7
寒风裹雪落长天,河水冰封漫白烟。
野树凝霜鸦雀静,苍茫一片锁江川。
0.7 已经达到一般对话的默认温度。几个动词的选择比较巧妙,而抒情部分不太明确,似乎全在写景。
V3 @ 温度 1.3
昨夜风吹雪缦徊,晨玫满树率先开。
冰封五里银河水,未见乌鹊架桥来。
1.3 温度下的表现相当优秀。第二句“玫”字“曰石之美者”,是指美玉:“早晨整棵树都开满了洁白的美玉”,比喻令人拍案叫绝。第三句的“冰封银河水”表现也相当大气。最后抒情表达则含蓄地抒发了对美好事物未及时出现的淡淡惆怅,全诗相当优秀。
V3 @ 温度 1.8
玉英昨夜下天台,万里河山俱白头。
更有严寒流不住,凌澌声断使人愁。
1.8 温度几乎没有直接写景了,大部分都在抒情。天台山观雪,可见山上山下俱白。“凌澌”指的是流动的冰凌,冰凌断裂的声音让人无法诉说,只能寄托深切的愁思。虽然抒情,但是其实和写景部分的关系已经不大了:和二句“万里河山”等意向对应的情感应该更加磅礴,但是实际却已经走偏。
V3 @ 温度 2.0
琼妃凌塔咏志高,笑唤薛崔斗绿腰。
偶是普通欢聚叶,邮苗韵拨碧壖飙。
不知所云,显然此时模型已经被玩坏了。
诗词鉴赏会到此结束,有点扯远了…不过至此,应该可以明确看出温度对回答质量和倾向的影响了。
在使用 V3 时,模型的温度参数设置可以参考官方文档。不同的模型会有不同的推荐温度,但是范围上来说都是类似的。更重要的是根据模型的输出,来合理调整温度,以期达到自己的目的:
- 在数理,法律,严格的专业知识问答中,选择降低的温度;
- 而在发散性思维,头脑风暴,创意性工作时,可以适当调高温度。
为什么推理模型不支持温度
如果你看过 o1 或者 R1 的使用文档,可能会注意到它们专门写明了:
不支持的参数:
temperature
推理任务 (数学计算、逻辑推理、代码生成) 通常需要唯一正确答案,温度参数引入的随机性可能导致错误或矛盾结果。这些任务中,1+2 就应该等于 3,9.11 就应该比 9.8 要小,它们有着唯一的答案。在推理模型训练时,也是以这个前提进行并发展出模型的推理能力的。温度的设置在这种情况下变得没有意义:推理模型追求精确收敛,通用模型更强调可控的多样性。所以,问题又回到了模型选择上来:我们应根据任务类型 (解题或是创作) 进行权衡。
不同的话题,是不是应该新开一个聊天页面?
是的!
模型为了表现得拥有记忆,在默认情况下,当你发送新的一条消息时,前几次的问答内容也会被一并发送,以模拟“模型记得你刚才问了什么,所以你们是在聊天”的假象。用 DeepSeek 官方的一张图来说明,模型是没有记忆的,实际发生的事情类似这样:
也就是说,之前的问题和回答,可能会影响后续的回答结果。当然,这个上下文是有上限的,只会带上前面若干次 (一般是五到十条) 的内容。有限的上下文,也是聊着聊着 AI 会表现得“忘事儿”的原因。
另一方面,在聊天对话过程中切换话题时,尽管模型通常能够识别话题的转变,但仍存在混淆的可能性。这种混淆在推理模型中尤为明显,可能导致模型的推理过程出现偏差。因此,为确保对话的连贯性和准确性,建议在开启新话题时新建一个会话,以便模型从初始状态进行理解。同时,保留已有的会话记录,便于未来需要时继续之前的对话,这不仅提高了对话的灵活性,也增强了体验。
模型群聊和对话分支
使用 API 或者第三方 app 还有一些其他好处,比如同时接入多个大模型,向它们投放相同的问题,然后再对结果进行对比和采信。“兼听则明,偏信则暗”的古训在此时完美地得到了诠释:
另外一个个人非常喜欢的使用方式,是对话分支。在进行 AI 问答时,特别是学习和调研某方面的内容时,往往我会遵循“先总体后局部”的方式。也就是先让模型提供一个总括,它简略地包含若干要点,提供一种综述性的知识。而在之后,我可能会对其中某几项感兴趣,进行深入问答。但是默认的单一的聊天会话会导致上下文丢失,让我一次只能专注于一个方面。此时,使用支持分支的工具,可以让我们在保持上下文清晰的情况下,对所有的方面 (以及进一步衍生出来的话题) 逐个展开深入,而不需要担心丢失上下文。比如下面这样的使用方式:
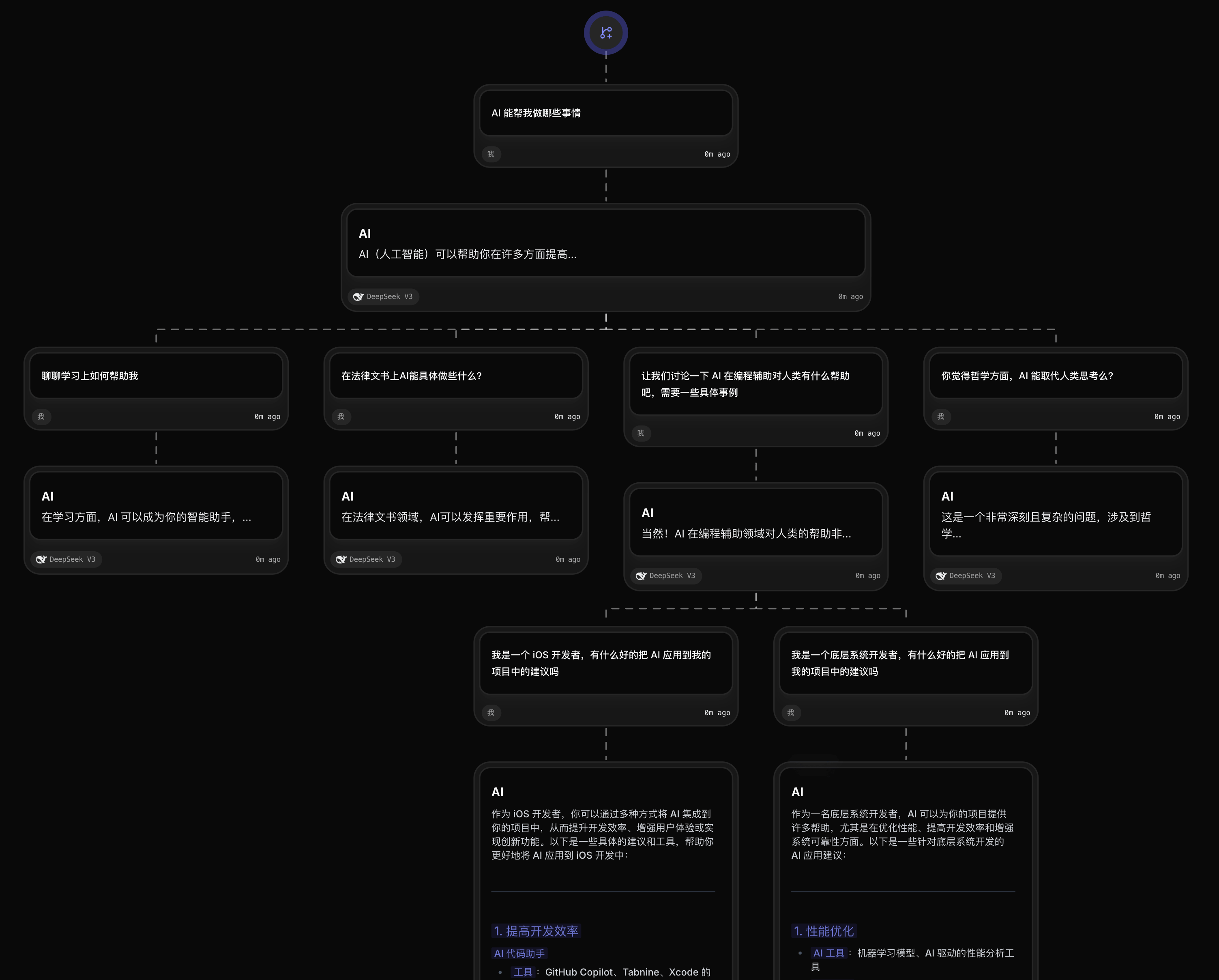
图中服务是 flowith.io,这里是我的邀请链接,如果有需要的话可以使用。当然,我前面提到的一些其他工具也有提供类似的功能,但是可视化上 flowith 做到了顶尖。
关于 R1 和社区提供的蒸馏模型
R1 蒸馏模型是什么,有什么用
所谓知识蒸馏,你可以理解为在训练新模型 (专业术语称为“学生模型”) 的时候,是通过向已有的模型 (或者叫做 “教师模型”) 提问来进行的。学生模型在提问和对比教师模型“答案”的过程中,不断调整自己的参数,让结果尽量逼近教师模型。
DeepSeek 在发布 R1 时,同时提供了几个蒸馏模型,像是 DeepSeek-R1-Distill-Qwen-7B 或者 DeepSeek-R1-Distill-Llama-70B。一个我常看到的误解,是认为这些参数较小的模型 (分别有 7B 个参数和 70B 参数),是通过蒸馏满血版 R1 (671B 参数) 得到的。其实不然,它们分别是通过蒸馏 Qwen 和 Llama 得到的。总结整个 R1 训练的整个过程:
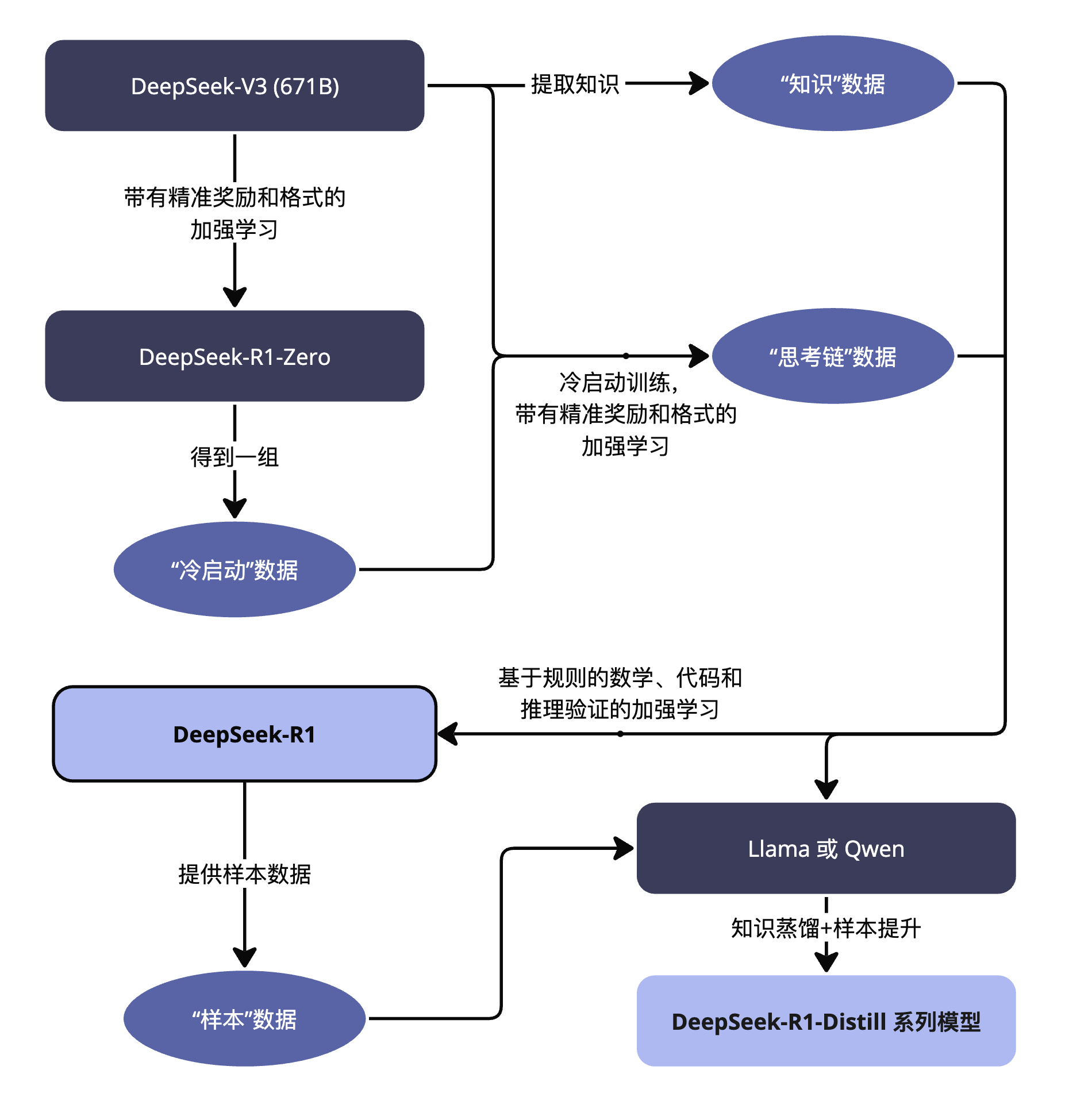
在 R1 蒸馏的过程中,DeepSeek 团队提到了“使用 R1 的样本数据”,但是基底模型还 Llama 和 Qwen。简单来说,可以认为通过思考链数据,DeepSeek 将 Llama 和 Qwen 这样的通用模型,蒸馏出了思考能力,让它们变身成了推理模型。类似的手段其实可以使用在其他任何模型上,现实是已经有一些团队在进行相关尝试了。
那么这些蒸馏模型有什么用呢?
最大的意义首先是有限资源下的部署:更小的参数意味着更低的运行需求,而同样参数的推理模型,表现普遍要比通用模型要优秀。一个开源、可以本地运行、而且效果还不错的 AI,将极大促进社会各个层面对于 AI 化的适配。
其次是提供给更多研究者和开发人员学习及探索的机会:不论是进一步微调,还是进行领域适配和改进,它们都是不错的参考和对比。另外,这些模型相当于对照组:因为明面上这样的蒸馏没有涉及到加强学习 (RL),所以它们相当于一种“只用 SFT 能走多远”的实验对照,可以帮助研究者了解不借助 RL 时,SFT 到什么程度能赋予模型推理能力。
虽然 R1 的 Distill 系列模型并非直接通过 DeepSeek-R1 蒸馏,但 R1 的产品协议明确用户可进行“模型蒸馏”,也就是说大家可以自由地利用模型输出 (甚至包括思考链的内容)、通过模型蒸馏等方式训练其他模型。这极大降低了模型训练的门槛,必定将会促进更多推理模型涌现。
HuggingFace 上的社区模型都是什么意思
如果你到 HuggingFace 搜索“DeepSeek”,除了官方版本的模型外,你还会看到很多社区版本的模型。当前,大部分模型通过 GGUF 格式发布,比如这个社区版本的模型。在 Model Card 中,我们会看到更多的版本,比如:

这里的 3-bit,4-bit 等,指模型经过量化 (Quantization) 处理后参数的存储位数。量化是模型压缩的常见技术,它将原先模型的每个参数从高精度 (比如 16 位的浮点数) 转换为低精度 (比如 4 位整数),从而减少模型体积和计算资源需求。但同时,参数精度的损失也意味着结果精度的损失。另外,模型文件上的大写字母,代表量化时采用的方法,具体情况可以参考相关说明。
自己部署 R1 蒸馏模型的设备需求
在本机部署模型的教程已经有一大堆了,无非就是 ollama 啊 llama.cpp 之类,在此不再赘述。如果想要一键无脑,那么 LM Studio 是更好的选择,直接下载,加载,GUI 界面以及提供 API 一气呵成,是尝鲜把玩的首选。
对于 14B 版本的 4bit 量化模型来说,在 16GB 的丐版 Mac mini 上部署是没有压力的,速度也完全可以接受。而往上一层的 32B,32GB 的 mac 也比较吃力,可能需要 48GB 的内存。70B 的“高配版”蒸馏在 4bit 下可以跑在 64GB 统一内存的 mac 上。如果想要在 Windows 环境和显卡上运行,则可以把要求对应到 VRAM + RAM 上进行评估。没有进行过量化的 70B 模型,需要内存 180GB,目前常见的消费级单机应该只有 192GB 内存的 Mac Studio Ultra 能跑,略过不表。
不过,我们需要对这些蒸馏模型的能力有一定认识:它们性能也许无法达到你的期望,特别是当使用过满血版的 R1 或是其他同等和更高等水平的模型后,落差感会更大。有朋友总结了一个很有意思的参数能力对照表,分享给大家:
1B:电子鹦鹉,简单判断对错
7-10B:单词机,抽关键词,多模态场景,语音,图文,过滤
30B:仅次于通用,路由,前置,抽正文,总结,超大上下文
70B:通用模型替代,什么都干
600B+:线上 API 投入实际生产
怎么满世界都在说集成 DeepSeek-R1
蹭热度的同时,其实也是在进行技术科普。虽然大部分集成可能只是小参数甚至量化版,但是这可以提高 AI 的全民参与度,让这项技术非常迅速地普及。低成本优势和开源特性,使得 R1 的接入异常方便,就算不是自己部署,企业或者个人也完全有能力承担 API 的调用开销。这种像水电一样的基础设施式的推广,会让终端应用爆发,最终促进整个行业发展,形成燎原之势和独特且深入人心的生态。
关于这方面的讨论,也可以参看我之前的一篇关于 AI 的文章。