![]()
我最近写了一个小框架 Chroma,用 Swift 在终端里做代码高亮;顺手还以它为基底做了一个(实验性的)cat 替代品 ca,能以带高亮的方式在终端里显示代码文本内容 (几乎和 bat 一样,只是又一个“I can, why not”的项目)。这篇文章想做三件事:先简单宣传一下(真的很短),然后重点聊聊这次实践中的主要收获:在 AI 驱动的迭代方式下,把性能优化这件事做“到底”变得前所未有地容易;最后再补一些在做 ca 期间学到的命令行设计和主题生态方面的东西。
Chroma / ca:一个很小的 promotion
Chroma 的目标非常朴素:给它一段代码和一个语言标识,它就返回一段可以直接 print 的 ANSI 彩色字符串。
语法高亮这种东西其实早就被写烂了:Rust 有 syntect,Python 有 Pygments,前端世界里更是 highlight.js 一类的工具满天飞。但我在 Swift 生态里一直没找到一个足够顺手、又能对终端输出细节(diff / 行号 / 行背景 / 缩进)有足够掌控力的选择,于是干脆自己(准确地说:靠 AI)糊了一个。
你可以把它塞进任何 Swift 的 CLI / TUI 工具里:渲染配置、渲染示例代码、渲染日志片段,或者把 git diff 变得更可读一点。这个库现在还只提供面向终端的渲染,不过设计上留了扩展口,将它扩展到 HTML 或者 AttributedString 都不算难。
最简单的用法大概就是这样:
1
2
3
4
5
6
7
8
9
10
11
import Chroma
let code = """
struct User {
let id: Int
let name: String
}
"""
let output = try Chroma.highlight(code, language: .swift)
print(output)
然后是 ca:它是一个 由 Chroma 驱动的 cat replacement(相比 cat 你甚至可以少输入一个字母),支持多文件、通过文件检测语言、主题设置、行号、分页等等。想要尝鲜的话,可以通过 Homebrew 直接安装:
1
2
3
4
brew install onevcat/tap/ca
# 然后就可以用它打印文件了
ca Chroma.swift
结果:
Chroma 负责把字符串按语言解析成 token,然后渲染成带样式的段,而具体 ANSI 的样式输出由我另一个库 Rainbow 提供。所以你可以认为 Chroma = tokenizer + renderer + theme + ANSI (来自 Rainbow)。
性能优化
关于 Chroma 的语言定义、主题和 diff 高亮等细节,其实并没有什么惊喜的地方;这次的实践我最迫不及待和大家分享的,其实是性能优化上的一些体会和心得。由于这种库天生对性能的要求,这次我花了不少时间在优化上:和最初的可用版本的性能相比,最终我在 AI 的帮助下将 tokenizer 和 renderer 的性能提升了十倍。
如果你也写过这类字符串密集型的库,就会知道性能优化有一个天然的尴尬:没有 benchmark 的时候,说“更快了”只能靠感觉;而有了 benchmark,想找热点就得反复剖析、试错、再测。问题不在于我们不会优化,而在于 试错成本太高。
在手工时代的性能优化大概是这样的:你凭直觉分析一下,也许行得通,然后花力气改一版,跑一下 benchmark;发现没变快(甚至变慢),啊..不行不行,那就改回去;再凭另一个直觉改一版再跑……重复两三次之后,人的耐心基本就被耗光了。更别提很多优化只有在压测/真实数据/极端输入下才能显形,它甚至不会立刻给你反馈。
而这次做 Chroma,我几乎完整体验了一次“AI 驱动的性能工程”。流程也不神秘:
- 让 AI 读代码、找热点、提出多个可替代方案
- 通过缜密的理论计算,预测各个方案能带来的提升效果
- 每次只做一个相对小的改动
- 立刻跑 benchmark,用结果驱动下一步,并改善之前的计算模型
它带来的最重要变化不是“某个聪明绝顶的微优化”,而是:
当试错不再昂贵时,你才真的会愿意把优化做完。
基准测试:让 AI 形成闭环
我把 benchmark 当成“优化的一等公民”。Chroma 仓库里记录了若干次迭代(以 commit 为粒度)的优化日志,这些数据会落到 JSON 结果文件里,然后我再把趋势画成图。
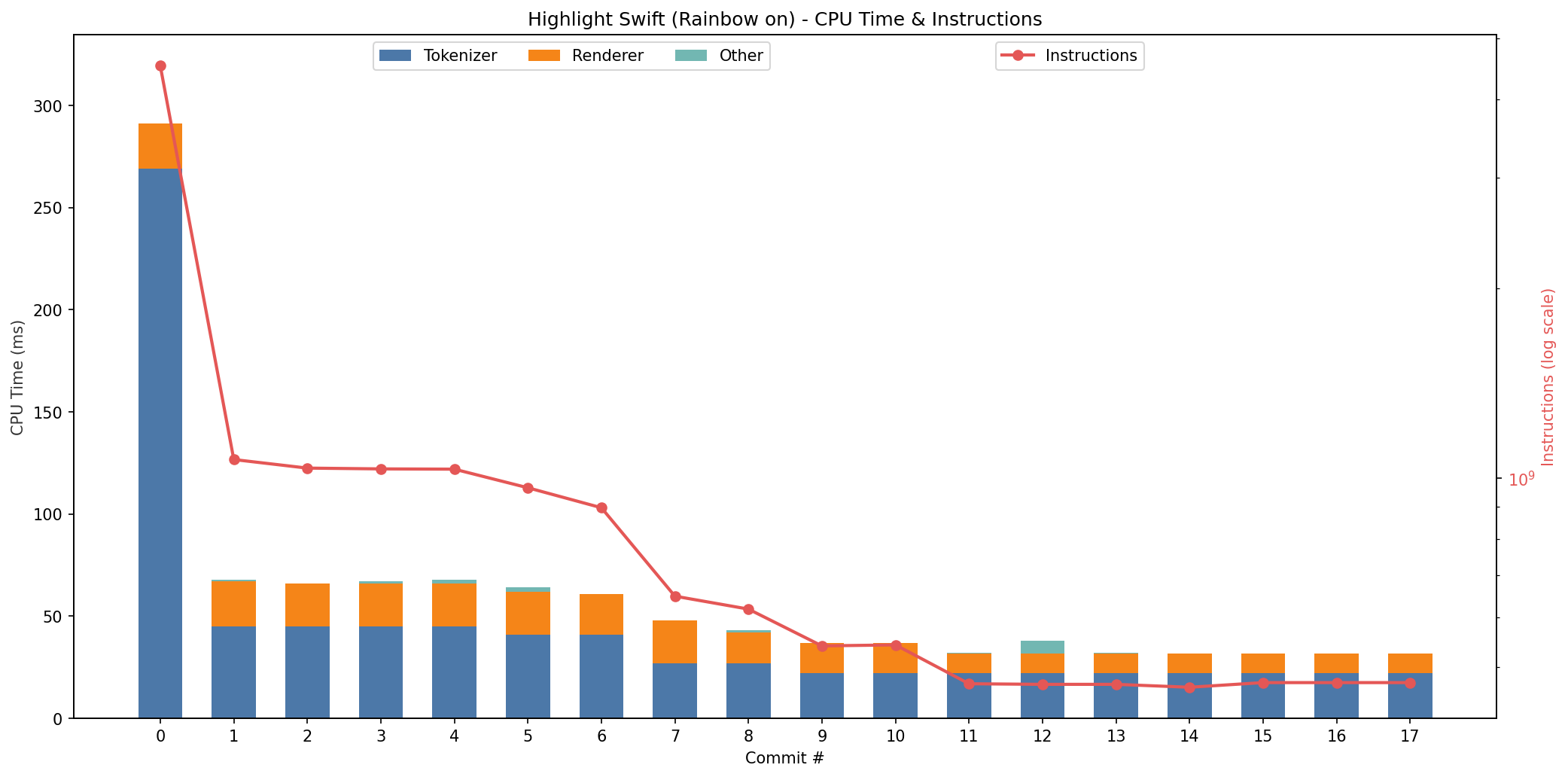
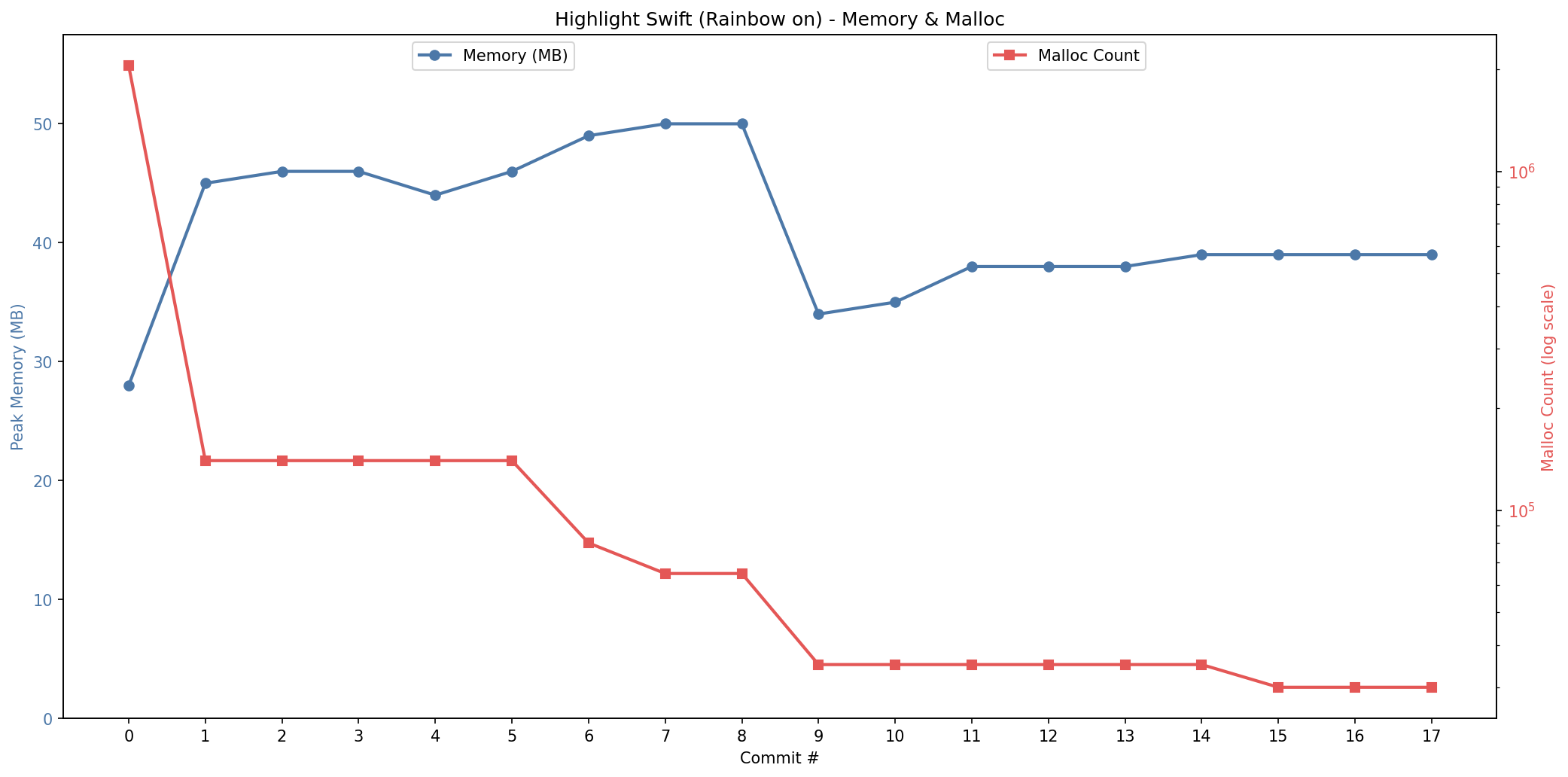
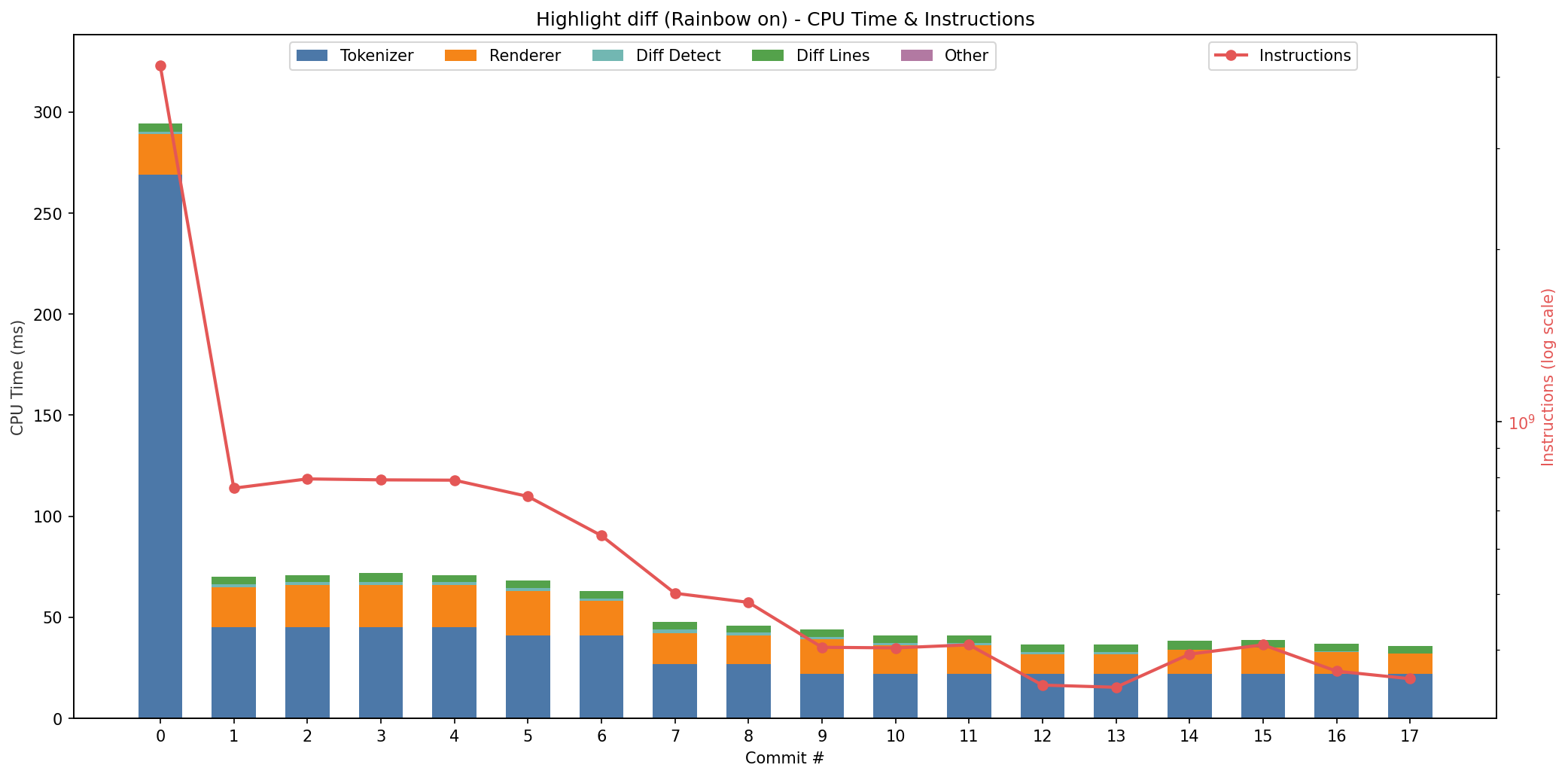
下面四张图基本概括了这次迭代的主线(Swift 高亮与 diff 高亮,各自的 CPU 与内存)。
Swift 高亮的 CPU 时间
Swift 高亮的内存占用
Diff 高亮的 CPU 时间
Diff 高亮的内存占用
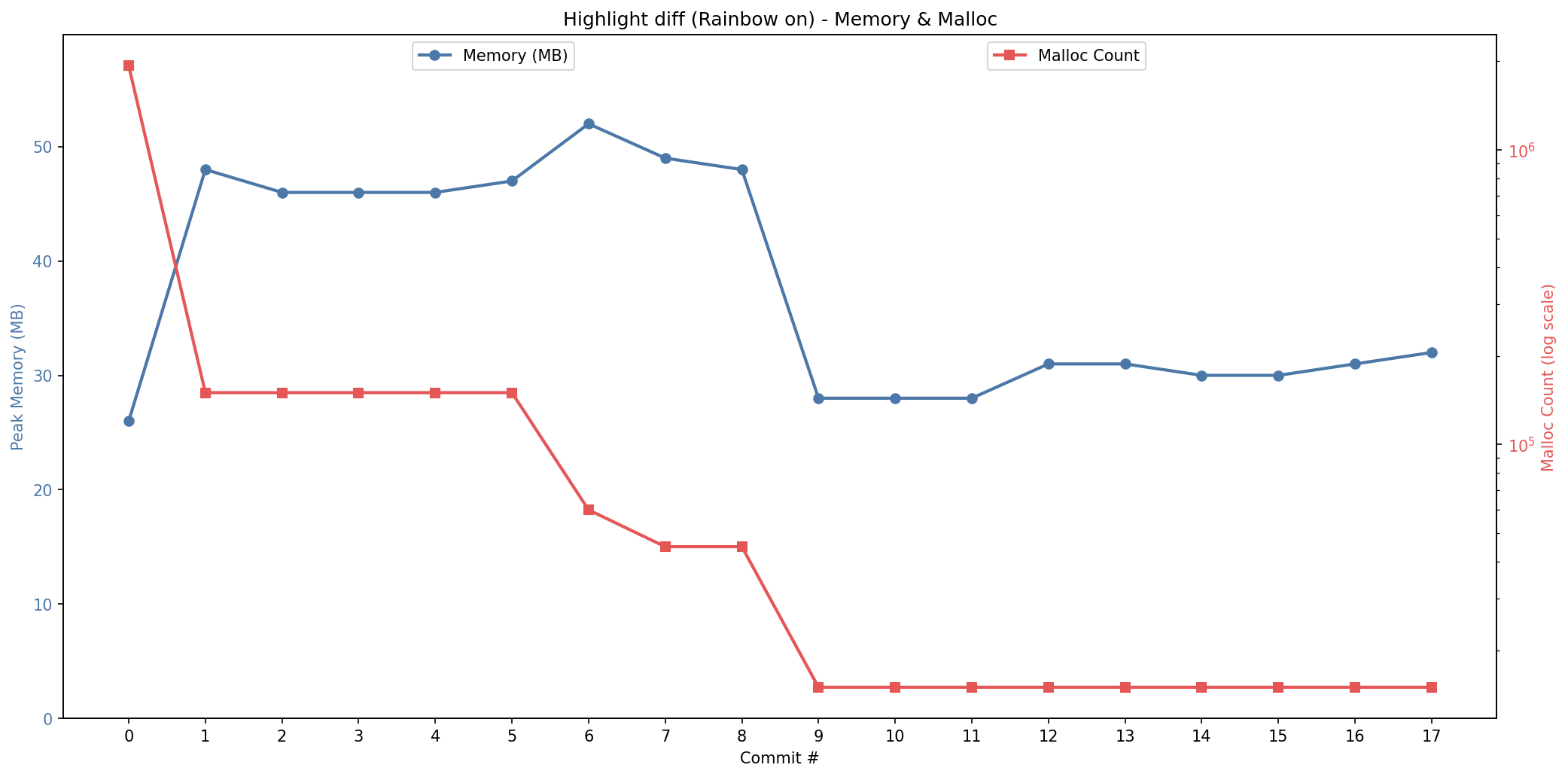
从趋势上看,有几件事非常直观。
首先,整体在往下走,这当然是好事。其次,过程中能明显看到 CPU 时间和内存占用在互相拉扯:有些改动更像是在用内存换速度,有些则反过来。
另外中间有一次小回撤(大概在第 13/14 次之间),看起来有点“怎么变慢了”,但这种波动其实很符合现实:这两次优化之间我插入了一些其他的功能性改动(比如支持不同的 diff 样式),热路径上多几个判断,往往就会出现这种回归。
最后,重要的是收敛:速度和内存占用最终落在了一个我愿意带到日常工具里用的“舒服区间”。
这些观察放在一起,其实就是“用 benchmark 驱动迭代”的价值:它把主观感受变成客观指标,让 AI 和人都能沿着同一条标尺前进。
两个典型优化:为什么能快这么多
优化日志里记录了不少 commit,我这里挑了两个我觉得有代表性的例子。
例 1:从 batch 到 streaming
早期一个关键节点是把 tokenizer / renderer 的流水线从“先生成完整 token 数组”变成“边扫边吐”(streaming / callback)。
这类改动对人来说其实挺烦的:涉及 API 改动、调用方适配、一些边界条件(比如 token 合并、换行处理)……它不是一个“改两行就快”的技巧,而是一个工程活。
但它的收益往往也是系统性的:少了中间数组的峰值内存,临时对象和拷贝会显著减少;再把相邻 token 合并(token coalescing)做对之后,渲染段数也会跟着变少。
这种“要动刀子、但很值”的活,在 AI 辅助下反而变得更容易:因为你可以让它把所有受影响的文件都扫一遍,逐个修到能跑为止;而你只需要盯着 benchmark 和测试,保证它不走偏。
例 2:ASCII fast-path 与 UTF-16 buffer
另一类典型优化是“针对现实输入分布的 fast path”。源码文本绝大部分是 ASCII:关键字、操作符、标点、以及大多数标识符都逃不出 0~127。
如果每次都走 String.Index、composed character 这些更昂贵的路径,其实是在为极少发生的情况支付“常态成本”。
所以这里做了一个比较朴素但很有效的策略:先判断是否 ASCII-only;是的话在热循环里用更便宜的方式前进(甚至直接用 UTF-16 buffer 做更快的访问);遇到非 ASCII 再回退到安全路径。
这类优化的“难点”不是想不到,而是验证:你得保证不会把 emoji / CJK / 组合字符弄坏,同时要确保快路径真的快,而不是“快路径写得更慢”。
AI 在这里的优势很直接:它可以一边补测试守住 correctness,一边不断跑 benchmark 验证收益;更重要的是,它不会像人一样在第三次失败后开始烦躁。
对人来说,最耗人的往往不是写那段代码,而是那种“我又要试一次、跑一次、分析一次”的心力。
一个旁支:Rainbow 的 plainText 的性能问题
在做 benchmark 时还碰到一个很有意思的现象:在某些情况下,Rainbow.enabled = false(也就是禁用 ANSI 输出)居然并不比开启 ANSI 更快。
追下去才发现,Chroma 在 Rainbow 关闭时走了 Rainbow.Entry.plainText,而当时 Rainbow 的实现里有一个 reduce("", +) 的拼接模式,在总长度上是 O(n^2) 的。于是出现了“关了反而不快”的反直觉现象。由于这个发现,我甚至有机会修了一个 Rainbow 的性能陷阱!
这件事给我的启发是:benchmark 真的是照妖镜,很多“理所当然”都经不起测;而一旦你愿意把 benchmark 当成日常工具,这种隐藏问题就会非常自然地浮出水面。
我真正想强调的:AI 的价值是降低试错成本
如果把这次经历总结成一句话,我可能会写成:
AI 让性能优化从“偶尔做做”变成了“可以持续推进到满意为止”。
这是一个十分重要的转变,我愿意把它叫做一种“超越人性”的改变。性能优化本质其实是科学实验:提出假设、设计实验、收集数据、得出结论。以前阻碍我们做实验的最大因素是“实验太贵”。而当实验成本被压到足够低,人的行为模式会自然改变:你会更愿意去验证、更愿意去重构、更愿意去把边界条件想全。
在这个意义上,10 倍的性能提升当然很爽,但更重要的是:它把你从“优化三次就累了”的上限里解放出来。我相信这样的工程范式的转换会在今后越来越多,也越来越频繁的发生在我们的日常之中。
开发杂谈:CLI 设计、主题生态
做 ca 这种命令行工具,最有意思的其实不是写代码,而是“该怎么让它像个命令行工具”。GUI 的世界里大家习惯了“按钮给你兜底”,而 CLI 的世界里,设计更像一种契约:你要提前决定什么该去 stdout,什么该去 stderr;什么时候该安静,什么时候该啰嗦;默认值选成什么样,才不会打扰用户、也不会让用户踩坑。
clig.dev:把最佳实践搬到自己这里
我这次读了不少相关资料,其中很推荐 clig.dev,它把很多命令行设计的常识写得非常清晰:输出、错误、颜色、交互、文档、退出码……都很“工程化”。
更有趣的是,“读资料”这件事本身也发生了变化:我顺手让 AI 翻译成中文,再顺手把它架到一个网站上 https://clig.onev.dev 。从 fork 到发布整个过程可能只花了我一小时,而后续边读边改,让这个网站又多了一点可复用的价值。
放在以前,这种事情大概会成为一个“有点想做但太麻烦”的坑;现在基本上属于“想做就做,当天搞定”。这件事对我最大的意义是:很多知识如果不被缓存到自己可重复访问的地方,就很容易随着时间被冲淡。
主题:Base46 让我意识到“生态”本身就是功能
ca 作为一个读代码的工具,主题几乎就是体验的上限。
我以前对“主题系统”不是很上心,总觉得它属于“锦上添花”。但这次把 Chroma 的主题做起来后,我才意识到:主题不是颜色表,它更像是一个工具的“性格”;而主题生态越大,用户越容易找到熟悉感。
Chroma 里我引入了 Base46 的主题集合(对应 ChromaBase46Themes 模块)。它的好处其实也很朴素:世界上已经有大量优秀主题,与其自己闭门造车,不如提供一个很薄的适配层,让一个新工具可以很快“继承”成熟审美。
这也很符合我越来越相信的一件事:当你把工具做成一个可扩展的核心时,很多“看起来很大”的东西其实可以通过生态来补齐。
在此之前,我甚至不知道 base46 主题这个东西。这个概念和相关的想法,完全是从 @yetone 的一篇推文中得到的启发。这里也顺便为 yetone 大佬的 Alma 宣传一波,真的是一个非常优雅的后 Chatbot 时代的工具(我愿意把它叫做 Goose 的超级威力加强版!)
总结
软件工程里很多所谓“最佳实践”,不是因为它们多么正确,而是因为它们能让协作更顺畅、让成本更可控。
能被量化的东西,才会被持续改进。而当你真的体验过一次由 benchmark 驱动的闭环迭代,你会发现,当初显得难以完成的高成本任务,现在变得触手可及。当 AI 把“写代码”这件事变便宜之后,很多成本会从编码转移到别处。工程的难度转移到了别处:设立指标、建立验证、持续测试、形成闭环等。新时代的开发,更重要的可能是建立一套能够持续改善和“自我治理”的体系,而维持这套体系所需要的成本,反而显得不再那么关键。
这可能是我从 Chroma(以及这次优化)里带走的最大收获。