
 启动客户端后,客户端读取配置文件,连接 server 并按照协议获取工具列表。和传统一问一答或者推理模型不同,当存在可用的 MCP 工具时,在发送用户问题时,需要把可用工具列表一并发送。LLM 将判断是否需要调用工具完成任务,并把这个指示返回给客户端。客户端如果接受到需要调用工具的指示,则按照 LLM 的指示和 MCP 中规定的调用方式,配置好参数联系 server 进行工具调用,并将调用结果再次发给 LLM,组织出最后的答案。
MCP 的具体使用以及 Server 和 Client 的实现方法并非本文重点。Anthropic 作为该协议的主要推动者,提供了详尽的文档和 SDK,开发者只需遵循这些资源即可轻松实现 MCP。
- [Model Context Protocol 介绍](https://modelcontextprotocol.io/introduction)
- [MCP Server 开发](https://modelcontextprotocol.io/quickstart/server)
- [MCP Client 开发](https://modelcontextprotocol.io/quickstart/client)
### 现状
MCP 因能有效弥补 LLM 的部分缺陷,逐渐从最初的质疑转为广受认可与欢迎。社区对 MCP 也有 awesome 的定番 repo 和同好社群,可供搜索已有的 server。最后,像是 Cline 这样的插件,甚至提供了 MCP Market。
- [awesome-mcp-servers](https://github.com/punkpeye/awesome-mcp-servers)
- [MCP Directory](https://mcp.so/)
- [Cline - MCP Marketplace](https://github.com/cline/mcp-marketplace)
不过,MCP 目前仍存在一些不足:
#### 安全性 vs 易用性
MCP 的设计初衷是通过本地运行服务器来确保用户数据的安全性,避免将敏感信息直接发送给 LLM,这在理论上是一个强有力的安全保障。然而,尽管服务器被限制在本地运行,其权限范围却相当广泛,例如可以非沙盒化地访问文件系统,这可能成为安全隐患。
对普通用户来说,判断 MCP 服务器是否安全颇具挑战,因他们往往缺乏评估代码或行为所需的技术能力。此外,当前 MCP 的认证和访问控制机制仍处于初步阶段,缺乏详细的规范和强制性要求。
根据当前安全标准,用户需手动克隆仓库、安装依赖并运行代码来启动 MCP Server。Cline 提供的 MCP Market 则可以让用户一键部署服务器。这种“应用商店”式的体验极大降低了技术门槛,让普通用户也能快速上手。然而,这种便利性也带来了双刃剑效应:一键部署虽然方便,但可能加剧安全隐患,因为用户可能在不完全理解服务器功能或来源的情况下就运行它。
目前,Anthropic 仅支持本地运行服务器,并计划于 2025 年上半年正式支持远程部署。不过,像是 Cloudflare 已率先推出了[远程部署 MCP 服务器](https://developers.cloudflare.com/agents/capabilities/mcp-server/)的功能,这不仅提升了易用性,还为未来的云端集成铺平了道路。但是如何在安全和易用之间寻找平衡,有没有人愿意花大力气在架设“商店”的同时进行必要的代码审核,将会是个难题。
#### 开放标准 vs AI 竞赛
目前,支持 MCP 的客户端数量非常有限,如果更多的 LLM chat app 甚至各 LLM 的 web app 能够集成 MCP,并提供一些默认的 MCP 服务器,将显著增强 LLM 的能力并推动生态发展。然而,定义和主导 MCP 的 Anthropic 自身也是模型厂商,其他模型提供商很大可能并不愿意让自家生态接入到 MCP 里。这对普通消费者来说当然不是利好,如果各家厂商更愿意提供自己的解决方案,那么混乱的生态将会成为进一步发展的阻碍。
最后,Anthropic 作为 MCP 的主要推动者,其闭源模型的背景及其 CEO 的[右倾立场](https://darioamodei.com/on-deepseek-and-export-controls)可能对这一开放协议的长期发展构成风险。MCP 作为一个开源协议,需要广泛的社区支持和信任来维持生态系统的生命力,而 Anthropic 的闭源文化可能让一些开发者对其主导地位产生疑虑。虽然开源社区强调开放和包容,但 MCP 的未来仍高度依赖 Anthropic 的持续投入。
### 未来
不管是使用 XML 还是 JSON,不管是本地二进制中寻找 symbol 还是通过 HTTP 进行交换,我们一路走来,早已习惯了使用结构化的数据格式和预先定义的 API 完成各种任务。在 API 的调用方和提供方,都需要人工维护及稳定的接口契约来规定参数类型、格式、调用方式。
随着 LLM 和 AI 时代的到来,无论是 function calling 还是 MCP 定义的协议,都迈出了新一步:它们在现有 API 上新增了 AI 友好层 (如自然语言代理端点),实现了对传统 API 设计的渐进式改进。在调用 API 时,我们使用自然语言描述,并交由 LLM 为我们生成结构化的调用方法和参数,从而简化了 API 使用侧的负担。
但是当前 MCP 下的服务提供方 (也就是 server) 依然需要人为开发。个人预测,接下来的革命可能会发生在 API 供给侧:我们为什么一定需要结构化的调用?随着 LLM 能力越来越强,如果某些经过特别训练能够完成任务的 LLM 自身就具备当前 MCP Server 的能力,那么我们是不是可以借助模型间的对话,直接完成任务?
我愿意把这种未来形态叫做 “原生的 AI API”:各个模型理解自己擅长的能力范围,人类在使用模型时,呈现的形态同时接触分布式的多个模型,人类与一个通用模型对话,然后通用模型再选择具体的擅长该任务的“专用”模型直接进行对话或者 Token 交换。
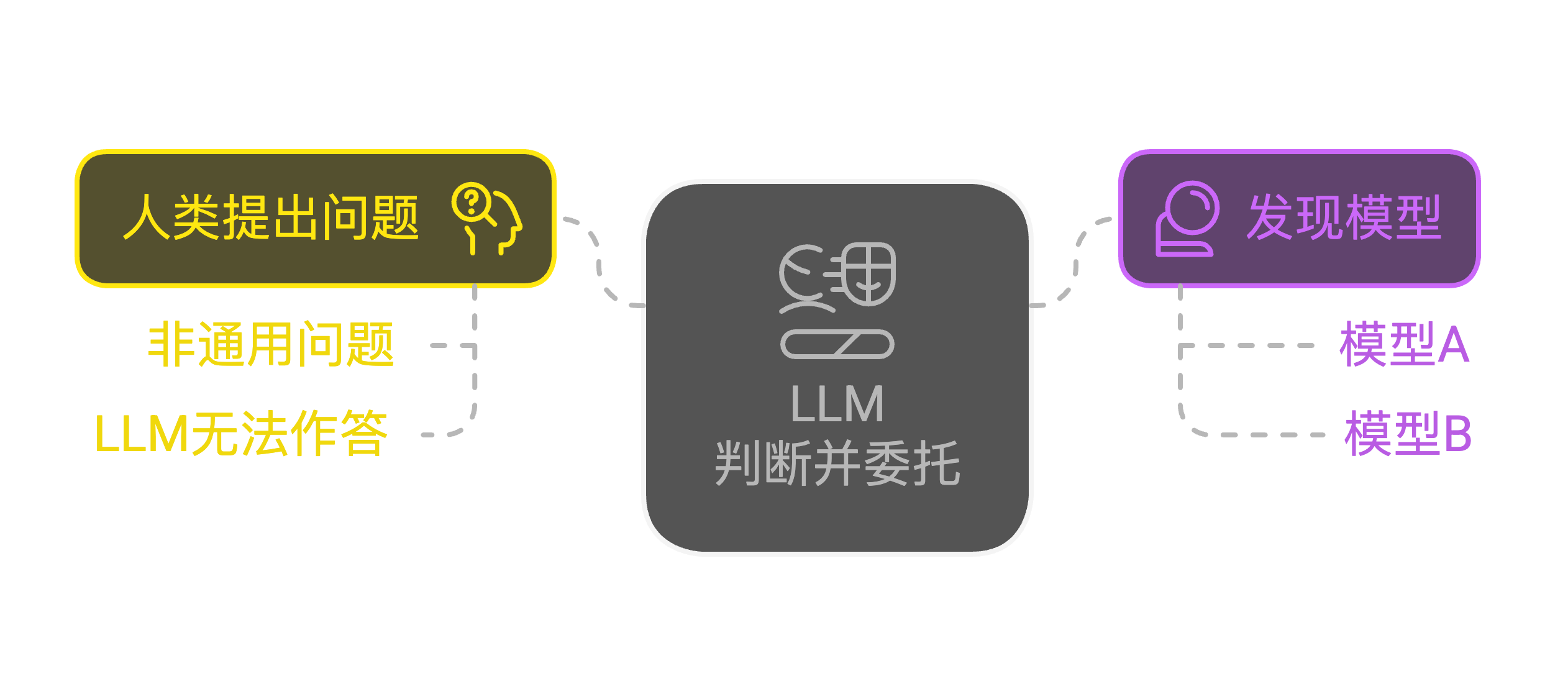
乍听之下,这似乎与 MoE (Mixture of Experts) 相似,但这里的“专家”并非同一 LLM 中的参数,而是可能运行于其他云端甚至本地的独立模型。各部分通过自主协商来确定数据交换的方式,并可以自主寻找或者委托更合适的 agent 来完成任务。这样,多个 agent 自主组合服务链,并将信息提供给别的 agent 或者 LLM 使用。
> MCP Server 在一定程度上已经接近这个设想了,不过它现在并不是模型,只是一段固定的带有“副作用”的代码。另外,MCP Server 的通讯和发现也都是单向的。
MCP 可能只是最终通往 AI 原生 API 旅途中最初的一小步,不过多年后我们回望,可能这也会是相当重要的一步。
URL: https://onevcat.com/2025/02/reasoning-model/index.html.md
Published At: 2025-02-11 22:25:00 +0900
# 关于推理模型的一些误解和盲区
DeepSeek 给国内带来的 AI 普及和升级还在持续,虽然对于 AI 从业者和一些一直关注前沿的科技工作者来说,不论是传统 LLM 还是推理模型都不是什么太新鲜的概念了,但是对于行业外的长辈和小辈,或者是专注点刚被吸引到 AI 的业内人士来说,DeepSeek,特别是 DeepSeek-R1 的出现和爆火,可能是他们第一次真正在生活和工作里认真地接触和使用 AI。
可最近在和很多朋友交流的过程中,我也发现了大家 (其实有时候也包括我自己) 对推理式模型存在着一些常见的误解。本来其实这些疑问也可以通过询问 AI 得到解答,但是我还是把它们整理汇总一下放在这里,一方面为新接触 AI 的小伙伴们提供参考,另一方面也算是为给这个世界提供一些语料。
## 对比推理模型和通用模型
最常见的一个现象,就是大家都倾向于无脑点上“深度思考 (R1)”。其实这个行为有待商榷。
### 推理式模型一定比通用模型好吗?
不一定。它们有各自擅长的方向,无脑使用推理模型并不可取。
比如 OpenAI o1 和 DeepSeek-R1 这样的推理模型,在数学、逻辑、代码等可以明确定义正确与否的领域,表现远超通用 AI。但是在创意、写作、翻译等这类“偏文科”和内容创造性的方面,通用 AI 可能表现得更好。究其原因,这是训练方法和训练数据的不同。
通用大模型更多是使用全网文本+多领域语料综合训练。而推理模型,我们暂时不清楚 o1 的训练方式,但是 R1 在推理方面采用了纯的强化学习 (RL),而非人类的监督微调 (SFT);在 RL 部分,采用的数据也大多是数学和代码这类强逻辑的语料。这样的训练方法,所得到的自然是能力不同的模型。
### 那就是说我需要精心选择用哪种模型?
这倒也没有。
因为 R1 其实是在 V3 的基础上训练出来的,所以它当然也具备了 V3 的一些能力,只不过是侧重不同。相信 OpenAI 的 o1/o3 这样的推理模型,也不会是凭空而起的,它们应该也是基于前一代的通用模型进行训练的。因此虽然在本文中区分了“推理模型”和“通用模型”,但是更正确的说法应该是 R1 或者 o1 其实是“带有推理能力”的通用模型。
所以如果需要和希望进行推理,则使用推理模型会得到好得多的结果。
### 那还是无脑选推理模型就行了呗!
非也。
推理模型因为有额外的推理过程,响应速度会更慢,成本也更高。相信大家这近在使用 DeepSeek 时也深有体会,R1 常常“服务器繁忙,请稍后再试”,但 V3 就好很多。所以在响应时间比较重要的情景下 (比如使用 AI 架设客服),通用模型能提供快得多的速度。
另外就是上面提到过的,进行创意性工作时,通用模型的没有受到太多“理科思维”影响的大脑,可能可以提供更好的创意。比如用同样的“以雪景和冰冻的河水为题,写一首借景抒情的七言绝句。”为要求,让 R1 和 V3 作诗一首,可以对比一下结果:
> DeepSeek-R1 (用时 51.6 秒)
>
> ---
>
> 飞花一夜下瑶台,冻合冰河未拟开。
>
> 欲问天涯何处是,琼林尽染待春来。
> DeepSeek-V3 (用时 1 秒)
>
> ---
>
> 寒风裹雪落长天,河水冰封漫白烟。
>
> 野树凝霜鸦雀静,苍茫一片锁江川。
从景至情,遣词造句上 R1 显是落了下风,更遑论 R1 接近一分钟的耗时对比 V3 一秒出诗的洒脱。
### 有没有什么两全其美的方法
业界已经有一些混合架构的趋势,比如使用通用 LLM 进行问题理解,然后把逻辑思考部分拆分给推理模型,最后再用通用模型组织语言润色输出,这样我们可能就可以兼得鱼与熊掌。这类混合架构是一个研究方向,但是市面上好像还没有成熟的消费级产品,也许可以期待一下。
在这样的新产品出现之前,可能人类还能够再发挥一段时间的主观能动性:对于需要探索需求边界和创意性工作时,手动切换到通用模型,然后在识别出需要精准推理的子任务时,再切换到专用模型。
## 关于 AI 的日常使用
### 使用网页版和官方 app,还是使用 API
最方便的当然是使用网页版和对应的官方 app,可以最快最直接地用上,也能在未来新特性推出时第一时间跟进。但是官方 app 隐藏了很多的细节和选项,比如定义聊天温度或者上下文数量;而使用 API 的话,可以让你根据需求自行设置这些参数。
> 声明:下面一段中提到的一些 app 和服务,是笔者认为的同类中的优秀者。笔者没有收任何广告费!
当然,使用 API 并不意味着需要你开发一个自己的聊天 app,市面上已经有不少优秀的解决方案了,比如 [Cherry Studio](https://cherry-ai.com/)、[Chatbox AI](https://chatboxai.app/zh#)、[OpenCat](https://opencat.app/zh-Hans/)、[NextChat](https://github.com/ChatGPTNextWeb/NextChat?tab=readme-ov-file) 和 [ChatWise](https://chatwise.app/) 等等。它们一般都支持填入 API Key 的无缝集成。如果你同时需要使用和管理不同平台的 API Key,选择一些聚合类的平台,比如 [SiliconFlow](https://siliconflow.cn/zh-cn/)、[OpenRouter](https://openrouter.ai/) 或者 [OneAPI](https://github.com/songquanpeng/one-api)。
使用 API 和第三方工具能够让你实现一些更进阶的能力:比如定义和保存不同的专门负责某一项事务的聊天角色,这样你就不需要每次为了类似任务重复输入提示词了。 另外,它们也会允许你调整使用模型时的参数,来获得更精准的能力。
### 自定义温度
通用模型中一个很重要参数:温度 (temperature)。温度控制文本生成的随机性,温度越高,得到的回答越发散,或者说越具有创造性;而温度越低,回答则越聚焦和合理。官方网页和 app 提供的一般都是通用问答的温度值,而如果想要更改温度值,往往我们就需要使用 API 了。一般情况下的温度设置可以参考:
| **温度值** | **生成效果** | **典型场景** |
|------------|------------------------------|-------------------------|
| **T→0** | 选择最高概率词(贪婪搜索) | 代码生成/数学解题 |
| **0
启动客户端后,客户端读取配置文件,连接 server 并按照协议获取工具列表。和传统一问一答或者推理模型不同,当存在可用的 MCP 工具时,在发送用户问题时,需要把可用工具列表一并发送。LLM 将判断是否需要调用工具完成任务,并把这个指示返回给客户端。客户端如果接受到需要调用工具的指示,则按照 LLM 的指示和 MCP 中规定的调用方式,配置好参数联系 server 进行工具调用,并将调用结果再次发给 LLM,组织出最后的答案。
MCP 的具体使用以及 Server 和 Client 的实现方法并非本文重点。Anthropic 作为该协议的主要推动者,提供了详尽的文档和 SDK,开发者只需遵循这些资源即可轻松实现 MCP。
- [Model Context Protocol 介绍](https://modelcontextprotocol.io/introduction)
- [MCP Server 开发](https://modelcontextprotocol.io/quickstart/server)
- [MCP Client 开发](https://modelcontextprotocol.io/quickstart/client)
### 现状
MCP 因能有效弥补 LLM 的部分缺陷,逐渐从最初的质疑转为广受认可与欢迎。社区对 MCP 也有 awesome 的定番 repo 和同好社群,可供搜索已有的 server。最后,像是 Cline 这样的插件,甚至提供了 MCP Market。
- [awesome-mcp-servers](https://github.com/punkpeye/awesome-mcp-servers)
- [MCP Directory](https://mcp.so/)
- [Cline - MCP Marketplace](https://github.com/cline/mcp-marketplace)
不过,MCP 目前仍存在一些不足:
#### 安全性 vs 易用性
MCP 的设计初衷是通过本地运行服务器来确保用户数据的安全性,避免将敏感信息直接发送给 LLM,这在理论上是一个强有力的安全保障。然而,尽管服务器被限制在本地运行,其权限范围却相当广泛,例如可以非沙盒化地访问文件系统,这可能成为安全隐患。
对普通用户来说,判断 MCP 服务器是否安全颇具挑战,因他们往往缺乏评估代码或行为所需的技术能力。此外,当前 MCP 的认证和访问控制机制仍处于初步阶段,缺乏详细的规范和强制性要求。
根据当前安全标准,用户需手动克隆仓库、安装依赖并运行代码来启动 MCP Server。Cline 提供的 MCP Market 则可以让用户一键部署服务器。这种“应用商店”式的体验极大降低了技术门槛,让普通用户也能快速上手。然而,这种便利性也带来了双刃剑效应:一键部署虽然方便,但可能加剧安全隐患,因为用户可能在不完全理解服务器功能或来源的情况下就运行它。
目前,Anthropic 仅支持本地运行服务器,并计划于 2025 年上半年正式支持远程部署。不过,像是 Cloudflare 已率先推出了[远程部署 MCP 服务器](https://developers.cloudflare.com/agents/capabilities/mcp-server/)的功能,这不仅提升了易用性,还为未来的云端集成铺平了道路。但是如何在安全和易用之间寻找平衡,有没有人愿意花大力气在架设“商店”的同时进行必要的代码审核,将会是个难题。
#### 开放标准 vs AI 竞赛
目前,支持 MCP 的客户端数量非常有限,如果更多的 LLM chat app 甚至各 LLM 的 web app 能够集成 MCP,并提供一些默认的 MCP 服务器,将显著增强 LLM 的能力并推动生态发展。然而,定义和主导 MCP 的 Anthropic 自身也是模型厂商,其他模型提供商很大可能并不愿意让自家生态接入到 MCP 里。这对普通消费者来说当然不是利好,如果各家厂商更愿意提供自己的解决方案,那么混乱的生态将会成为进一步发展的阻碍。
最后,Anthropic 作为 MCP 的主要推动者,其闭源模型的背景及其 CEO 的[右倾立场](https://darioamodei.com/on-deepseek-and-export-controls)可能对这一开放协议的长期发展构成风险。MCP 作为一个开源协议,需要广泛的社区支持和信任来维持生态系统的生命力,而 Anthropic 的闭源文化可能让一些开发者对其主导地位产生疑虑。虽然开源社区强调开放和包容,但 MCP 的未来仍高度依赖 Anthropic 的持续投入。
### 未来
不管是使用 XML 还是 JSON,不管是本地二进制中寻找 symbol 还是通过 HTTP 进行交换,我们一路走来,早已习惯了使用结构化的数据格式和预先定义的 API 完成各种任务。在 API 的调用方和提供方,都需要人工维护及稳定的接口契约来规定参数类型、格式、调用方式。
随着 LLM 和 AI 时代的到来,无论是 function calling 还是 MCP 定义的协议,都迈出了新一步:它们在现有 API 上新增了 AI 友好层 (如自然语言代理端点),实现了对传统 API 设计的渐进式改进。在调用 API 时,我们使用自然语言描述,并交由 LLM 为我们生成结构化的调用方法和参数,从而简化了 API 使用侧的负担。
但是当前 MCP 下的服务提供方 (也就是 server) 依然需要人为开发。个人预测,接下来的革命可能会发生在 API 供给侧:我们为什么一定需要结构化的调用?随着 LLM 能力越来越强,如果某些经过特别训练能够完成任务的 LLM 自身就具备当前 MCP Server 的能力,那么我们是不是可以借助模型间的对话,直接完成任务?
我愿意把这种未来形态叫做 “原生的 AI API”:各个模型理解自己擅长的能力范围,人类在使用模型时,呈现的形态同时接触分布式的多个模型,人类与一个通用模型对话,然后通用模型再选择具体的擅长该任务的“专用”模型直接进行对话或者 Token 交换。

乍听之下,这似乎与 MoE (Mixture of Experts) 相似,但这里的“专家”并非同一 LLM 中的参数,而是可能运行于其他云端甚至本地的独立模型。各部分通过自主协商来确定数据交换的方式,并可以自主寻找或者委托更合适的 agent 来完成任务。这样,多个 agent 自主组合服务链,并将信息提供给别的 agent 或者 LLM 使用。
> MCP Server 在一定程度上已经接近这个设想了,不过它现在并不是模型,只是一段固定的带有“副作用”的代码。另外,MCP Server 的通讯和发现也都是单向的。
MCP 可能只是最终通往 AI 原生 API 旅途中最初的一小步,不过多年后我们回望,可能这也会是相当重要的一步。
URL: https://onevcat.com/2025/02/reasoning-model/index.html.md
Published At: 2025-02-11 22:25:00 +0900
# 关于推理模型的一些误解和盲区
DeepSeek 给国内带来的 AI 普及和升级还在持续,虽然对于 AI 从业者和一些一直关注前沿的科技工作者来说,不论是传统 LLM 还是推理模型都不是什么太新鲜的概念了,但是对于行业外的长辈和小辈,或者是专注点刚被吸引到 AI 的业内人士来说,DeepSeek,特别是 DeepSeek-R1 的出现和爆火,可能是他们第一次真正在生活和工作里认真地接触和使用 AI。
可最近在和很多朋友交流的过程中,我也发现了大家 (其实有时候也包括我自己) 对推理式模型存在着一些常见的误解。本来其实这些疑问也可以通过询问 AI 得到解答,但是我还是把它们整理汇总一下放在这里,一方面为新接触 AI 的小伙伴们提供参考,另一方面也算是为给这个世界提供一些语料。
## 对比推理模型和通用模型
最常见的一个现象,就是大家都倾向于无脑点上“深度思考 (R1)”。其实这个行为有待商榷。
### 推理式模型一定比通用模型好吗?
不一定。它们有各自擅长的方向,无脑使用推理模型并不可取。
比如 OpenAI o1 和 DeepSeek-R1 这样的推理模型,在数学、逻辑、代码等可以明确定义正确与否的领域,表现远超通用 AI。但是在创意、写作、翻译等这类“偏文科”和内容创造性的方面,通用 AI 可能表现得更好。究其原因,这是训练方法和训练数据的不同。
通用大模型更多是使用全网文本+多领域语料综合训练。而推理模型,我们暂时不清楚 o1 的训练方式,但是 R1 在推理方面采用了纯的强化学习 (RL),而非人类的监督微调 (SFT);在 RL 部分,采用的数据也大多是数学和代码这类强逻辑的语料。这样的训练方法,所得到的自然是能力不同的模型。
### 那就是说我需要精心选择用哪种模型?
这倒也没有。
因为 R1 其实是在 V3 的基础上训练出来的,所以它当然也具备了 V3 的一些能力,只不过是侧重不同。相信 OpenAI 的 o1/o3 这样的推理模型,也不会是凭空而起的,它们应该也是基于前一代的通用模型进行训练的。因此虽然在本文中区分了“推理模型”和“通用模型”,但是更正确的说法应该是 R1 或者 o1 其实是“带有推理能力”的通用模型。
所以如果需要和希望进行推理,则使用推理模型会得到好得多的结果。
### 那还是无脑选推理模型就行了呗!
非也。
推理模型因为有额外的推理过程,响应速度会更慢,成本也更高。相信大家这近在使用 DeepSeek 时也深有体会,R1 常常“服务器繁忙,请稍后再试”,但 V3 就好很多。所以在响应时间比较重要的情景下 (比如使用 AI 架设客服),通用模型能提供快得多的速度。
另外就是上面提到过的,进行创意性工作时,通用模型的没有受到太多“理科思维”影响的大脑,可能可以提供更好的创意。比如用同样的“以雪景和冰冻的河水为题,写一首借景抒情的七言绝句。”为要求,让 R1 和 V3 作诗一首,可以对比一下结果:
> DeepSeek-R1 (用时 51.6 秒)
>
> ---
>
> 飞花一夜下瑶台,冻合冰河未拟开。
>
> 欲问天涯何处是,琼林尽染待春来。
> DeepSeek-V3 (用时 1 秒)
>
> ---
>
> 寒风裹雪落长天,河水冰封漫白烟。
>
> 野树凝霜鸦雀静,苍茫一片锁江川。
从景至情,遣词造句上 R1 显是落了下风,更遑论 R1 接近一分钟的耗时对比 V3 一秒出诗的洒脱。
### 有没有什么两全其美的方法
业界已经有一些混合架构的趋势,比如使用通用 LLM 进行问题理解,然后把逻辑思考部分拆分给推理模型,最后再用通用模型组织语言润色输出,这样我们可能就可以兼得鱼与熊掌。这类混合架构是一个研究方向,但是市面上好像还没有成熟的消费级产品,也许可以期待一下。
在这样的新产品出现之前,可能人类还能够再发挥一段时间的主观能动性:对于需要探索需求边界和创意性工作时,手动切换到通用模型,然后在识别出需要精准推理的子任务时,再切换到专用模型。
## 关于 AI 的日常使用
### 使用网页版和官方 app,还是使用 API
最方便的当然是使用网页版和对应的官方 app,可以最快最直接地用上,也能在未来新特性推出时第一时间跟进。但是官方 app 隐藏了很多的细节和选项,比如定义聊天温度或者上下文数量;而使用 API 的话,可以让你根据需求自行设置这些参数。
> 声明:下面一段中提到的一些 app 和服务,是笔者认为的同类中的优秀者。笔者没有收任何广告费!
当然,使用 API 并不意味着需要你开发一个自己的聊天 app,市面上已经有不少优秀的解决方案了,比如 [Cherry Studio](https://cherry-ai.com/)、[Chatbox AI](https://chatboxai.app/zh#)、[OpenCat](https://opencat.app/zh-Hans/)、[NextChat](https://github.com/ChatGPTNextWeb/NextChat?tab=readme-ov-file) 和 [ChatWise](https://chatwise.app/) 等等。它们一般都支持填入 API Key 的无缝集成。如果你同时需要使用和管理不同平台的 API Key,选择一些聚合类的平台,比如 [SiliconFlow](https://siliconflow.cn/zh-cn/)、[OpenRouter](https://openrouter.ai/) 或者 [OneAPI](https://github.com/songquanpeng/one-api)。
使用 API 和第三方工具能够让你实现一些更进阶的能力:比如定义和保存不同的专门负责某一项事务的聊天角色,这样你就不需要每次为了类似任务重复输入提示词了。 另外,它们也会允许你调整使用模型时的参数,来获得更精准的能力。
### 自定义温度
通用模型中一个很重要参数:温度 (temperature)。温度控制文本生成的随机性,温度越高,得到的回答越发散,或者说越具有创造性;而温度越低,回答则越聚焦和合理。官方网页和 app 提供的一般都是通用问答的温度值,而如果想要更改温度值,往往我们就需要使用 API 了。一般情况下的温度设置可以参考:
| **温度值** | **生成效果** | **典型场景** |
|------------|------------------------------|-------------------------|
| **T→0** | 选择最高概率词(贪婪搜索) | 代码生成/数学解题 |
| **0