
2014 年 7 月 13 日更新:根据 beta 3 的情况修正了文中过时的部分
从周一 Swift 正式公布,到现在周五,这几天其实基本一直在关注和摸索 Swift 了。对于一门新语言来说,开荒阶段的探索自然是激动人心的,但是很多时候资料的缺失和细节的隐藏也让人着实苦恼。这一周,特别是最近几天的感受是,Swift 并不像我上一篇表达自己初步看法的文章里所说的那样,相对于 objc 来说有更好的学习曲线。甚至可以说 objc 在除了语法上比较特别以外,其概念还是比较容易的。而 Swift 在漂亮的语法之后其实隐藏了很多细节和实现,而如果无法理解这些细节和实现,就很难明白这门新语言在设计上的考虑。在实际编码中,也会有各种各样的为什么编译不通过,为什么运行时出错这样的问题。本文意在总结一下这几天看 Swift 时候遇到的自己觉得重要的一些概念,并重新整理一些对这门语言的想法。可能有些内容是需要您了解 Swift 的基本概念的,所以这并不是一篇教你怎么写 Swift 或者入门的文章,建议您先读读 Apple 官方给出的 Swift 的电子书,至少将第一章的 Tour 部分读完(这里也有质量很不错的但是暂时还没有完全翻译完成的中文版本)。不过因为自己也才接触一周不到,肯定说不上深入,还希望大家一起探讨。
类型?什么是类型?
这是一个基础的问题,类型 (Types) 在 Swift 中是非常重要的概念,在 Swift 中类型是用来描述和定义一组数据的有效值,以及指导它们如何进行操作的一个蓝图。这个概念和其他编程语言中“类”的概念很相似。Swift 的类型分为命名类型和复合类型两种;命名类型比较简单,就是我们日常用的 类 (class),结构体 (struct),枚举 (enum) 以及接口 (protocol)。在 Swift 中,这四种命名类型为我们定义了所有的基本结构,它们都可以有自己的成员变量和方法,这和其他一般的语言是不太一样的(比如很少有语言的enum可以有方法,protocol可以有变量)。另外一种类型是复合类型,包括函数 (func) 和 多元组 (tuple)。它们在使用的时候不会被命名,而是由 Swift 内部自己定义。
我们在实际做开发时,一般会接触很多的命名类型。在 Swift 的世界中,一切看得到的东西,都一定属于某一种类型。在 PlayGround 或者是项目中,通过在某个实际的被命名的类型上 Cmd + 单击,我们就能看到它的定义。比如在 Swift 世界中的所有基本型 Int,String,Array,Dictionay 等等,其实它们都是结构体。而这些基本类型通过定义本身,以及众多的 extension,实现了很多接口,共同提供了基本功能。这也正是 Swift 的类型的一种很常见的组织方式。
而相对的,Cocoa 框架中的类,基本都被映射为了 Swift 的 class。如果你有比较深厚的 objc 功底的话,应该会听说过 objc 的类其实是一组包含了元数据 (metadata) 的结构体,而在 objc 中我们可以使用 +class 来拿到某个 Class 的 isa,从而确定类的组成和描述。而在 Swift 的 native 层面上,在 type safe 的基础上,不再需要 isa 来指导对象如何构建,而这个过程会通过确定的命名类型完成。正因为这个原因,Swift 中干脆把 NSObject 的 class 方法都拿掉,因为 Swift 和 ObjC 在这个根本问题上的分歧,最终导致了在使用 Swift 调用 Cocoa 框架时的各种麻烦和问题。
参照和值,Array和Dictionary背后的一些故事
2014 年 7 月 13 日更新 由于 beta 3 中
Array被完全重写,这一节关于Array的一些行为和表述完全过时了。 关于Array的用法现在简化了很多,请参见新加的 “真 参照和值,Array和Dictionary背后的一些故事”
如果你坚持看到了这里,那么恭喜你…本文最无趣和枯燥的部分已经结束了(同时也应该吓走了不少抱着玩玩看的心态来看待 Swift 的读者吧..笑),那么开始说一些细节的东西吧。
首先要明白的概念是,参照和值。在 C 系语言里摸爬滚打过的同学都知道,我们在调用一个函数的时候,往里传的参数有两种可能。一种是传递类似一个数字或者结构体这样的基本元素,这时候这个整数的值会被在内存中复制一份然后传到函数内部;另一种情况是传递一个对象,为了性能和内存上的考虑,这时候一般不会去将对象的内容复制一遍,而是会传递的一个指向同一块内存的指针。
在 Swift 中一个与其他语言都不太一样的地方是,它的 Collection 类型,也就是 Array 和 Dictionary,并不是 class 类型,而是 struct 结构体。那么按照我们以往的经验,在传值或者赋值的时候应该是会复制一份。我们来试试看是不是这样的~
1
2
3
4
5
6
7
8
9
10
11
12
13
var dic = [0:0, 1:0, 2:0]
var newDic = dic
//Check dic and newDic
dic[0] = 1
dic //[0: 1, 1: 0, 2: 0]
newDic //[0: 0, 1: 0, 2: 0]
var arr = [0,0,0]
var newArr = arr
arr[0] = 1
//Check arr and newArr
arr //[1, 0, 0]
newArr //[1, 0, 0]
Dictionary 的值没有问题,我们改变了 dic 中的值,但是 newDic 保持了原来的值,说明 newDic 确实被复制了一份。而当我们检查到 Array 的时候,发生了一点神奇的事情。虽然 Array 是 struct,但是当我们改变 arr 时,新的 newArr 也发生了改变,也就是说,arr 和 newArr 其实是同一个参照。这里的原因其实在 Apple 的官方文档中有一些说明。Swift 考虑到实际使用的情景,对 Array 做了特殊的处理。除非需要(比如 Array 的大小发生改变,或者显式地要求进行复制),否则 Array 在传递的时候会使用参照。
在这里如果你想要只改变 arr 的值,而保持新赋予的 newArr 不变的话,你需要显式地对 arr 进行 copy(),像下面这样。
1
2
3
4
5
6
var arr = [0,0,0]
var copiedArr = arr.copy()
arr[0] = 1
arr //[1, 0, 0]
copiedArr //[0, 0, 0]
这时候 arr 和 copiedArr 将指向不同的内存地址,对原来的数组重新赋值的时候,就不会再影响新的数组了。另一种等效的做法是通过 Array 的初始化方法建立一个新的 Array:
1
2
3
4
5
6
var arr = [0,0,0]
var newArr = Array(arr)
arr[0] = 1
arr //[1, 0, 0]
newArr //[0, 0, 0]
值得一提的是,对于 Array 这个 struct 的这种特殊行为,Apple 还准备了另一个函数 unshare() 给我们使用。unshare() 的作用是如果对象数组不是唯一参照,则复制一份,并将作用的参照指向新的地址(这样它就变成唯一参照,不会意外改变原来的别的同样的参照了);而如果这个参照已经是唯一参照了的话,就什么都不做。
1
2
3
4
5
6
7
8
9
10
var arr = [0,0,0]
var newArr = arr
//Breakpoint 1
arr.unshare()
//Breakpoint 2
arr[0] = 1
arr //[1, 0, 0]
newArr //[0, 0, 0]
这个设计的意图是为了更安全地使用这个优化过的行为奇怪的数组结构体。关于 unshare() 的行为,我们也可以通过使用 LLDB 断点来观察内存地址的变化。参见下图:

另外一个要加以注意的是,Array 在 copy 时执行的不是深拷贝,所以 Array 中的参照类型在拷贝之后仍然会是参照。Array 中嵌套 Array 的情况亦是如此:对一个 Array 进行的 copy 只会将被拷贝的 Array 指向新的地址,而保持其中所有其他 Array 的引用。当然你可以为 Array (或者准确说是 Array
真 参照和值,Array和Dictionary背后的一些故事
2014 年 7 月 13 日更新
Apple 在 beta 3 里重写了 Array,它的行为简化了许多。首先 copy 和 unshare 两个方法被删掉了,而类似的行为现在以更合理的方式在幕后帮我们完成了。还是举上面的那个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
var dic = [0:0, 1:0, 2:0]
var newDic = dic
//Check dic and newDic
dic[0] = 1
dic //[0: 1, 1: 0, 2: 0]
newDic //[0: 0, 1: 0, 2: 0]
var arr = [0,0,0]
var newArr = arr
arr[0] = 1
//Check arr and newArr
arr //[1, 0, 0]
newArr //before beta3:[1, 0, 0], after beta3:[0, 0, 0]
Dictionary 当然还是 OK,但是对于 Array 中元素的改变,在 beta 3 中发生了变化。现在不再存在作为一个值类型但是却在赋值和改变时表现为参照类型的 Array 的特例,而是彻头彻尾表现出了值类型的特点。这个改变避免了原来需要小心翼翼地对 Array 进行 copy 或者 unshare 这样的操作,而 Apple 也承诺在性能上没有问题。文档中提到其实现在的行为和之前是一贯的,只不过对于数组的复制工作现在是在背后由 Apple 只在必要的时候才去做。所以可以猜测其实在背后 Array 和 Dictionary 的行为并不是像其他 struct 那样简单的在栈上分配,而是类似参照那样,通过栈上指向堆上位置的指针来实现的。而对于它的复制操作,也是在相对空间较为宽裕的堆上来完成的。当然,现在还无法(或者说很难)拿到最后的汇编码,所以这只是一个猜测而已。最后如果能够证实对错的话,我会再进行更新。
总之,beta 3 之后,原来飘忽不定难以捉摸(其实真正理解之后还是很稳定的,也很适合出笔试题)的 Array 现在彻底简单化了。基本只需要记住它的行为在表面上和其他的值类型完全无异,而性能方面的考量可以交给 Apple 来做。
Array vs Slice
因为 Array 类型实在太重要了,因此不得不再多说两句。查看 Array 在 Swift 中的定义,我们可以发现其实 Array 实现了两个很重要的接口 MutableCollection 和 Sliceable。第一个接口比较简单,为 Array 实现了下标等特性,通过 Collection 通用的一些概念,可以从数据结构中获取元素,比较简单。而第二个接口 Sliceable 实现了通过 Range 来取出部分数组,这里稍微有点特殊。
Swift 引入了在其他很多语言中很流行的用 .. 和 ... (beta3 中 .. 被改成了 ..<,虽说是为了更明确的意义,但是看起来会比较奇怪)来表示 Range 的概念。从一个数组里面取出一个子数组其实是蛮普遍的一个需求,但是如果你足够细心的话,可能会发现我们无法写这样的代码:
1
2
3
var arr = [0,0,0]
var partOfArr: Array = arr[0...1]
//Could not find an overload for 'subscript' that accepts the supplied arguments
你会得到一个编译错误,告诉你没有重载下标。在我们去掉我们强制加上的 : Array 类型设置之后,编译能通过了。这就告诉我们,我们使用 Rang 从 Array 中取出来的东西,并不是 Array 类型。那它到底是个什么东西?使用 REPL 可以很容易看到,在使用 Range 从 Array 里取出来的其实是一个 Slice,而不是一个 Array。
1
2
3
4
5
6
7
8
9
10
11
1> var arr = [0,0,0]
arr: Int[] = size=3 {
[0] = 0
[1] = 0
[2] = 0
}
2> var slice = arr[0...1]
slice: Slice<Int> = size=2 {
[0] = 0
[1] = 0
}
So, what is a slice?查看 Slice 的定义,可以看到它几乎和 Array 一模一样,实现了同样的接口,拥有同样的成员,那么为什么不直接干脆给个爽快,而要新弄一个 Slice 呢?Apple gets crazy?当然不是..Slice的存在当然有其自己的价值和含义,而这和我们刚才提到的值和引用有一些关系。
So, why is a slice?让我们先尝试 play with it。接着上面的情况,运行下面的代码试试看:
1
2
3
4
5
6
7
8
9
10
var arr : Array = [0,0,0]
var slice = arr[0...1]
arr[0] = 1
arr //[1, 0, 0]
slice //[1, 0]
slice[1] = 2
arr //[1, 2, 0]
slice //[1, 2]
我想你已经明白一些什么了吧?这里的 slice 和 arr 当然不可能是同一个引用(它们的类型都不一样),但是很有趣的是,通过 Range 拿到的 Slice 中的元素,是指向原来的 Array 的。这个特性就非常有趣了,我们可以对感兴趣的数组片段进行观察或者操作,并且它们的值和原来的数组是对应的同步的。
理所当然的,在对应着的 Array 或者 Slice 其中任意一个的内存指向发生变化时(比如添加或移除了元素,重新赋值等等),这种关系就会被打破。
对于 Slice 和 Array,其实是可以比较简单地转换的。因为 Collection 接口是实现了 + 重载的,于是我们可以简单地通过相加来生成一个 Array (如果我们愿意的话)。不过,要是真的有需要的话,使用 Array 的初始化方法会是比较好的选择:
1
2
3
4
var arr : Array = [0,0,0]
var slice = arr[0...1]
var result1 : Array = [] + slice
var result2 : Array = Array(slice)
使用 Range 下标的方式,不仅可以取到这个 Range 内的 Slice,还可以对原来的数组进行批量”赋值”:
1
2
3
4
var arr : Array = [0,0,0]
arr[0...1] = [1,1]
arr //[1, 1, 0]
细心的同学可能注意到了,这里我把“赋值”打上了双引号。实际上这里做的是替换,数组的内存已经发生了变化。因为 Swift 没有强制要求替换的时候 Range 的范围要和用来替换的 Collection 的元素个数一致,所以其实这里一定会涉及内存的分配和新的数组生成。我们可以看看下面的例子:
1
2
3
4
5
6
7
8
9
var arr : Array = [0,0,0]
var otherArr = arr
arr[0...1] = [1,1]
arr //[1, 1, 0]
otherArr //[0, 0, 0]
arr[0..1] = [1,1]
arr //[1, 1, 1, 0]
给一个数组进行 Range 赋值,背后其实调用了数组的 replaceRange 方法,将取到的 Slice,替换成了赋给它的 Array 或者 Slice。而只要 Range 有效,我们就可以很灵活地写出类似这样的所谓的插入方法:
1
2
3
var arr : Array = [0,0,0]
arr[1..1] = [1, 1]
arr //[0, 1, 1, 0, 0]
这里的 1..1 是一个起点为 1,长度为 0 的Range,于是它取到的是原来 [0, 0, 0] 中 index 为 1 的位置的一个空 Slice,将其替换为 [1, 1]。清楚明白。
既然都提到了这么多次 Range,还是需要说明一下这个 Swift 里很重要的概念(其实在 objc 里 NSRange 也很重要,只不过没有像 Swift 里这么普遍)。Range 结构体中有两个非常重要的值,startIndex 和 endIndex,它表示了这个 Range 的范围。而这个值永远是右开的,也就是说,它们会和 x..y 这样的表示中 x 和 y 分别相等。对于 x < y 的情况下的 Range,是存在数学上的表达意义的,比如 2..1 这样的 Range 表示从 2 开始往前数 1。但是在实际从 Array 或者 Slice 中取值时这种表达是没有意义,并且会抛出一个运行时的 EXC_BAD_INSTRUCTION 的,在使用的时候还要加以注意。
颜文字很好,但是…
有了上面的一些基础,我们可以来谈谈 String 了。当说到我们可以在原生的 String 中使用 UniCode 字符时,全场一片欢呼。没错,以后我们可以把代码写成这样了!
1
2
3
let π = 3.14159
let 你好 = "你好世界"
let 🐶🐮 = "🐶🐮”
Cool…虽然我不认为有多少人会去把变量名弄成中文或者猫猫狗狗,但是毕竟字符串本身还是需要支持中文日文阿拉伯文甚至 emoji 的对吧。
另外一个很赞的是,Apple 把所有 NSString 的方法都“移植”到了 String 类型上,而且将 Cocoa 框架中所有涉及 NSString 的地方都换成了 String。这是一件很棒的事情,这意味着我们可以无缝在 Swift 上像原来写 objc 时候那样使用 String,而不必担心 String 和 NSString 之间类型转换等麻烦的问题。可能看过 session 或者细读了文档的同学会发现,新的 String 里,没有了原来的 -length 方法,取而代之,Apple 推荐我们使用 countElements 来获取字符串的长度。这是很 make sense 的一件事情,因为我们无法确定字符串中每个字符的字节长度,所以 Apple 为了帮助我们方便计算字符数,给了这个 O(N) 的方法。
这样的字符串带来了一个挺不方便的结果,那就是我们无法直接通过 Int 的下标来访问 String 中的字符。我们查看 Swift 中 String 的定义,可以看到它其实是实现了 subscript (i: String.Index) -> Character { get } 的(其 Range 访问也相应需要一个 Range<String.Index> 版本的泛型)。如果我们能知道字符对应的 String.Index,我们就可以写出方便的下标访问了。举个例子,如果有下面这样的两个 String。
1
2
var str = "1234"
var imageStr = "🐶🐱🐭🐰"
我们现在想要通过拿到上面那个 ASCII 字符串的某个数字所在的 String.Index,来获取下面对应位置的图标,比如 2 对应猫,应该如何做呢?一开始大概很容易想到这样的代码:
1
2
var range = str.rangeOfString("2") //记得导入 Cocoa 或者 UIKit
imageStr[range] //EXC_BAD_INSTRUCTION
很不幸,EXC_BAD_INSTRUCTION,这表示 Swift 中有一个 Assertion 阻止了我们继续。其实 String.Index 和一般的 Int 之类的 index 不太一样,因为每一个 Index 代表的字节的长度是有差别的,所以它只能实现 BidirectionalIndex,而不能像其他的等长结构那样实现 RandomAccessIndex 接口(关于这两个接口分别是什么已经做了什么,留给大家自己研究下吧)。于是,在不同字符串之间的 Index 进行转换时,我们大概不得不使用一种笨办法,那就是计算步长和差值。对于我们的例子,我们会先算出在 str 中 2 与初始 Index 的距离,然后讲这个距离在 imageStr 中以 imageStr 的 String.Index 进行套用,算出适合其的第二个字符的 Range,然后进行 Range 的下标访问,如下:
1
2
3
4
5
6
var range = str.rangeOfString("2")
var aDistance: Int = distance(str.startIndex, range.startIndex)
var imageStrStartIndex = advance(imageStr.startIndex, aDistance)
var range2 = imageStrStartIndex..imageStrStartIndex.successor()
var substring: String = imageStr[range2]
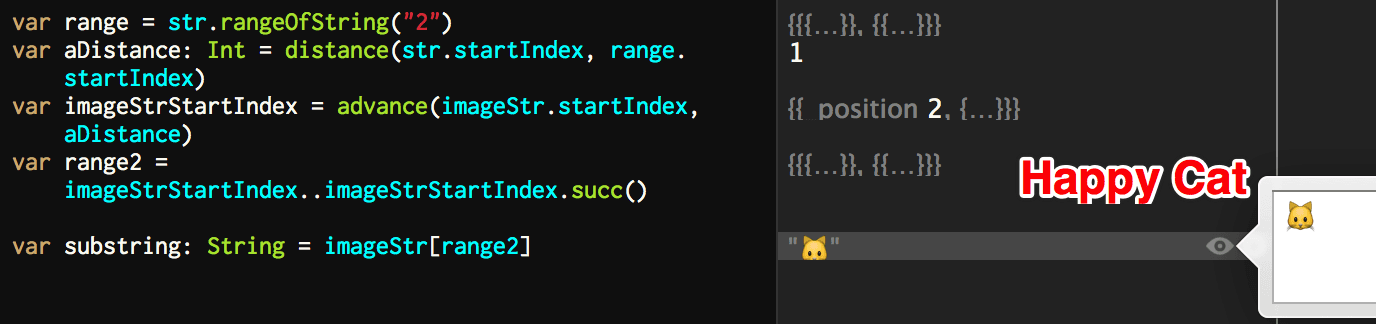
大部分时候其实我们不会这么来映射字符串,不过对于 Swift 字符串的实现和与 NSString 的差异,还是值得研究一番的。
幽灵一般的 Optional
Swift 引入的最不一样的可能就是 Optional Value 了。在声明时,我们可以通过在类型后面加一个 ? 来将变量声明为 Optional 的。如果不是 Optional 的变量,那么它就必须有值。而如果没有值的话,我们使用 Optional 并且将它设置为 nil 来表示没有值。
1
2
3
4
5
6
//num 不是一个 Int
var num: Int?
//num 没有值
num = nil //nil
//num 有值
num = 3 //{Some 3}
Apple 在 Session 上告诉我们,Optinal Value 其实就是一个盒子,你盒子里可能装着实际的值,也可能什么都没装。
我们看到 Session 里或者文档里天天说 Optional Optional,但是我们在代码里基本一个 Optional 都没有看到,这是为什么呢?而且,上面代码中给 num 赋值为 3 的时候的那个输出为什么看起来有点奇怪?其实,在声明类型时的这个 ? 仅仅只是 Apple 为了简化写法而提供的一个语法糖。实际上我们是有 Optional 类型的声明,就这里的 num 为例,最正规的写法应该是这样的:
1
2
3
4
//真 Optional 声明和使用
var num: Optional<Int>
num = Optional<Int>()
num = Optional<Int>(3)
没错,num 不是 Int 类型,它是一个 Optional 类型。到底什么是 Optional 呢,点进去看看:
1
2
3
4
5
6
7
8
9
10
11
12
13
enum Optional<T> : LogicValue, Reflectable {
case None
case Some(T)
init()
init(_ some: T)
/// Allow use in a Boolean context.
func getLogicValue() -> Bool
/// Haskell's fmap, which was mis-named
func map<U>(f: (T) -> U) -> U?
func getMirror() -> Mirror
}
你也许会大吃一惊。我们每天和 Swift 打交道用的 Optional 居然是一个泛型枚举 enum,而其实我们在使用这个枚举时,如果没有值,我们就规定这个枚举的是 .None,如果有,那么它就是 Some(value)(带值枚举这里不展开了,有不明白的话请看文档吧)。而这个枚举又恰好实现了 LogicValue 接口,这也就是为什么我们能使用 if 来对一个 Optinal 的值进行判断并进一步进行 unwrap 的依据。
1
2
3
4
5
6
7
var num: Optional<Int> = 3
if num { //因为有 LogicValue,
//.None 时 getLogicValue() 返回 false
//.Some 时返回 true
var realInt = num!
realInt //3
}
既然 var num: Int? = nil 其实给 num 赋的值是一个枚举的话,那这个 nil 到底又是什么?它被赋值到哪里去了?一直注意的是,Swift 里的 nil 和 objc 里的 nil 完全不是一回事儿。objc 的 nil 是一个实实在在的指针,它指向一个空的对象。而这里的 nil 虽然代表空,但它只是一个语意上的概念,确是有实际的类型的,看看 Swift 的 nil 到底是什么吧:
1
2
/// A null sentinel value.
var nil: NilType { get }
nil 其实只是 NilType 的一个变量,而且这个变量是一个 getter。Swift 给了我们一个文档注释,告诉我们 nil 其实只是一个 null 的标记值。实际上我们在声明或者赋值一个 Optional 的变量时,? 语法糖做的事情就是声明一个 Optional<T>,然后查看等号右边是不是 nil 这个标记值。如果不是,则使用 init(_ some: T) 用等号右边的类型 T 的值生成一个 .Some 枚举并赋值给这个 Optional 变量;如果是 nil,将其赋为 None 枚举。
所以说,Optional背后的故事,其实被这个小小的 ? 隐藏了。
我想,Optional 讨论到这里就差不多了,还有三个小问题需要说明。
首先,NilType 这个类型非常特殊,它似乎是个 built in 的类型,我现在没有拿到关于它的任何资料。我本身逆向是个小白,现在看起来 Swift 的逆向难度也比较大,所以关于 NilType 的一些行为还是只能猜测。而关于 nil 这一 NilType 的类型的变量来说,猜测的话,它可能是 Optional.None 的一种类似多型表现,因为首先它确实是指向 0x0 的,并且与 Optional.None 的 content 的内容指向一致。但是具体细节还要等待挖掘或者公布了。
2014 年 7 月 13 日更新 从 beta3 开始
nil是一个编译关键字了,NilType则被从 Swift 中移除了。这个改变解决了上面提到的很多悬而未决的问题,比如对 nil 的多次封装以及如何实现自己的可 nil 的类等等。现在添加了一个叫做NilLiteralConvertible的接口来使某个类可以使用 nil 语法,而避免了原来的让人费解的隐式转换。但是现在还有一个问题,那就是 Optional 是实现了LogicValue接口的,这就是得像BOOL?这样的类型在使用的时候会一不小心就很危险。
其次,Apple 推荐我们在 unwrap 的时候使用一种所谓的隐式方法,即下面这种方式来 unwrap:
1
2
3
4
5
6
var num: Int? = 3
if let n = num {
//have a num
} else {
//no num
}
最后,这样隐式调用足够安全,性能上似乎应该也做优化(有点忘了..似乎说过),推荐在 unwrap 的时候尽可能写这样的推断,而减少直接进行 unwrap 这种行为。
最后一个问题是 Optional 的变量也可以是 Optinal。因为 Optional 就相当于一个黑盒子,可以知道盒子里有没有东西 (通过 LogicValue),也可以打开这个盒子 (unwrap) 来拿到里面的东西 (你要的类型的变量或者代表没有东西的 nil)。请注意,这里没有任何规则限制一个 Optional 的量不能再次被 Optional,比如下面这种情况是完全 OK 的:
1
2
var str: String? = "Hi" //.Some("Hi")
var anotherStr: String?? = str //.Some(.Some("Hi"))
这其实是没有多少疑问的,很完美的两层 Optional,使用的时候也一层层解开就好。但是如果是 nil 的话,在这里就有点尴尬…
1
2
var str: String? = nil
var anotherStr: String?? = nil
因为我们在 LLDB 里输出的时候,得到了两个 nil
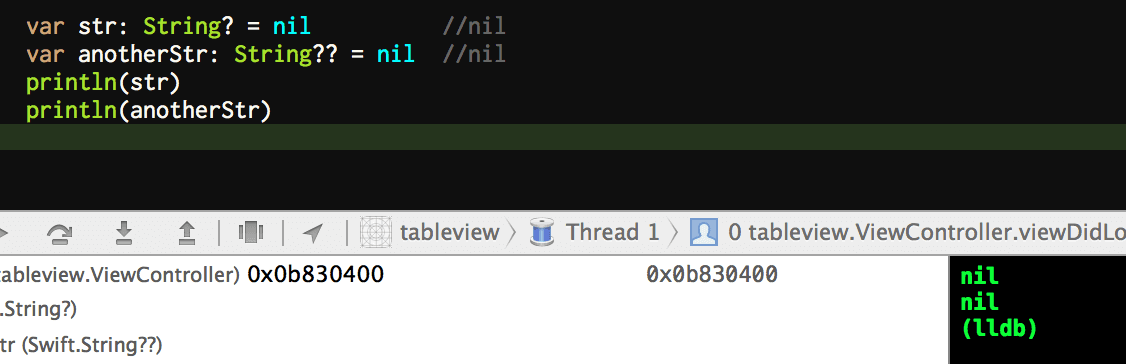
如果说 str 其实是 Optional<String>.None,输出是 nil 的话还可以理解,但是我们知道 (好吧,如果你认真读了上面的 Optional 的内容的话会知道),anotherStr 其实是 Optional<Optional<String>>.Some(Optional<String>.None),这是其实一个有效的非空 Optional,至少第一层是。而如果放在 PlayGround 里,anotherStr 得到的输出又是正确的 {nil}。What hanppened? Another Apple bug?
答案是 No,这里不是 bug。为了方便观察,LLDB 会在输出的时候直接帮我们尽可能地做隐式的 unwrap,这也就导致了我们在 LLDB 中输出的值只剩了一个裸的 nil。如果想要看到 Optional 本身的值,可以在 Xcode 的 variable 观察窗口点右键,选中 Show Raw values,这样就能显示出 None 和 Some 了。或者我们可以直接使用 LLDB 的 fr v -R 命令来打印整个 raw 的值:
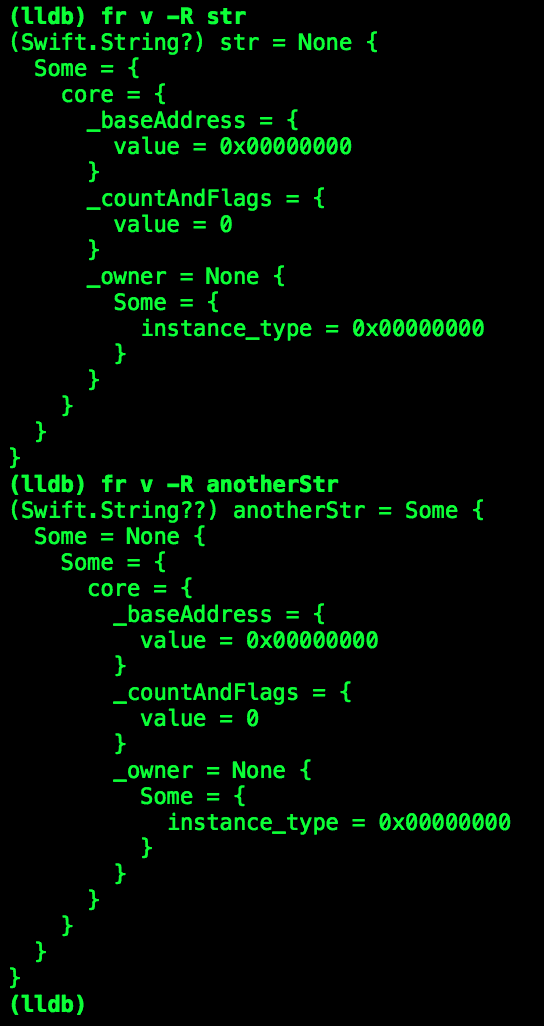
可以清楚看到,anotherStr 是 .Some 包了一个 .None。
(这里有个自动 unwrap 的小疑问,就是写类似 var anotherStr: String? = str 这样的代码也能通过,应该是 ? 语法在这里有个隐式解包,需要进一步确认)
? 那是什么??,! 原来如此!!
问号和叹号现在的用法都是原来 objc 中没有的概念。说起来简单也简单,但是背后也还是不少玄机。原来就已经存在的用法就不说了,这里把新用法从浅入深逐个总结一下吧。
首先是 ?:
?放在类型后面作为 Optional 类型的标记
这个用法上面已经说过,其实就是一个 Optional<T> 的语法糖,自动将等号后面的内容 wrap 成 Optional。给个用例,不再多说:
1
2
var num: Int? = nil //声明一个 Int 的 Optional,并将其设为啥都没有
var str: String? = "Hello" //声明一个 String 的 Optional,并给它一个字符串
?放在某个 Optional 变量后面,表示对这个变量进行判断,并且隐式地 unwrap。比如说:
1
foo?.somemethod()
相比起一般的先判断再调用,类似这样的判断的好处是一旦判断为 nil 或者说是 false,语句便不再继续执行,而是直接返回一个 nil。上面的写法等价于
1
2
3
if let maybeFoo = foo {
maybeFoo.somemethod()
}
这种写法更存在价值的地方在于可以链式调用,也就是所谓的 Optional Chaining,这样可以避免一大堆的条件分支,而使代码变得易读简洁。比如:
1
2
3
if let upper = john.residence?.address?.buildingIdentifier()?.uppercaseString {
println("John's uppercase building identifier is \(upper).")
}
注意最后 buildingIdentifier 后面的问号是在 () 之后的,这代表了这个 Optional 的判断对象是 buildingIdentifier() 的返回值。
?放在某个 optional 的 protocol 方法的括号前面,以表示询问是否可以对该方法调用
这中用法相当于以前 objc 中的 -respondsToSelector: 的判断,如果对象响应这个方法的话,则进行调用。例子:
1
delegate?.questionViewControllerDidGetResult?(self, result)
中的第二个问号。注意和上面在 () 后的问号不一样,这里是在 () 之前的,表示对方法的询问。
其实在 Swift 中,默认的 potocol 类型是没有 optional 的方法的,因为基于这个前提,可以对类型安全进行确保。但是 Cocoa 框架中的 protocol 还是有很多 optional 的方法,对于这些可选的接口方法,或者你想要声明一个带有可选方法的接口时,必须要在声明 protocol 时再其前面加上 @objc 关键字,并在可选方法前面加上 @optional:
1
2
3
4
5
@objc protocol CounterDataSource {
@optional func optionalMethod() -> Int
func requiredMethod() -> Int
@optional var optionalGetter: Int { get }
}
然后是 ! 新用法的总结
!放在 Optional 变量的后面,表示强制的 unwrap 转换:
1
foo!.somemethod()
这将会使一个 Optional<T> 的量被转换为 T。但是需要特别注意,如果这个 Optional 的量是 nil 的话,这种转换会在运行时让程序崩溃。所以在直接写 ! 转换的时候一定要非常注意,只有在有必死决心和十足把握时才做 ! 强转。如果待转换量有可能是 nil 的话,我们最好使用 if let 的语法来做一个判断和隐式转换,保证安全。
!放在类型后面,表示强制的隐式转换。
这种情况下和 ? 放在类型后面的行为比较类似,都是一个类型声明的语法糖。? 声明的是 Optional,而 ! 其实声明的是一个 ImplicitlyUnwrappedOptional 类型。首先需要明确的是,这个类型是一个 struct,其中关键部分是一个 Optional<T> 的 value,和一组从这个 value 里取值的 getter 和 方法:
1
2
3
4
5
6
7
struct ImplicitlyUnwrappedOptional<T> : LogicValue, Reflectable {
var value: T?
//...
static var None: T! { get }
static func Some(value: T) -> T!
//...
}
从外界来看,其实这和 Optional 的变量是类似的,有 Some 有 None。其实从本质上来说,ImplicitlyUnwrappedOptional 就是一个存储了 Optional,实现了 Optional 对外的方法特性的一个类型,唯一不同的是,Optional 需要我们手动进行进行 unwrap (不管是使用 var! 还是 let if 赋值,总要我们做点什么),而 ImplicitlyUnwrappedOptional 则会在使用的时候自动地去 unwrap,并对继续之后的操作调用,而不必去增加一次手动的显示/隐式操作。
为什么要这么设计呢?主要是基于 objc 的 Cocoa 框架的两点考虑和妥协。
首先是 objc 中是有指向空对象的指针的,就是我们所习惯的 nil。在 Swift 中,为了处理和 objc 的 nil 的兼容,我们需要一个可为空的量。而因为 Swift 的目的就是打造一个完全类型安全的语言,因此不仅对于 class,对于其他的类型结构我们也需要类型安全。于是很自然地,我们可以使用 Optional 的空来对 objc 做等效。因为 Cocoa 框架有大量的 API 都会返回 nil,因此我们在用 Swift 表达它们的时候,也需要换成对应的既可以表示存在,也可以表示不存在的 Optional。
那这样的话,不是直接用 Optional 就好了么?为什么要弄出一个 ImplicitlyUnwrappedOptional 呢?因为易用性。如果全部用 Optional 包装的话,在调用很多 API 时我们就都需要转来转去,十分麻烦。而对于 ImplicitlyUnwrappedOptional 因为编译器为我们进行了很多处理,使得我们在确信返回值或者要传递的值不是空的时候,可以很方便的不需要做任何转换,直接使用。但是对于那些 Cocoa 有可能返回 nil,我们本来就需要检查的方法,我们还是应该写 if 来进行转换和检查。
比如说,以下的写法就会在运行时导致一个 EXC_BAD_INSTRUCTION
1
2
3
let formatter = NSDateFormatter()
let now = formatter.dateFromString("not_valid")
let soon = now.dateByAddingTimeInterval(5.0) // EXC_BAD_INSTRUCTION
因为 dateFromString 返回的是一个 NSDate!,而我们的输入在原来会导致一个 nil 的返回,这里我们在使用 now 之前需要进行检查:
1
2
3
4
5
6
7
let formatter = NSDateFormatter()
let now = formatter.dateFromString("not_valid")
if let realNow = now {
realNow.dateByAddingTimeInterval(5.0)
} else {
println("Bad Date")
}
这和以前在 objc 时代做的事情差不多,或者,用更 Swift 的方式做
1
2
3
let formatter = NSDateFormatter()
let now = formatter.dateFromString("not_valid")
let soon = now?.dateByAddingTimeInterval(5.0)
如何写出正确的 Swift 代码
现在距离 Swift 发布已经接近小一周了。很多开发者已经开始尝试用 Swift 写项目。但是不管是作为练习还是作为真正的工程,现在看来大家在写 Swift 时还是带了浓重的 objc 的影子。就如何写出带有 Swift 范儿的代码,在这里给出一点不成熟的小建议。
- 理解 Swift 的类型组织结构。Swift 的基础组织非常漂亮,主要的基础类型大部分使用了
struct来完成,然后在之上定义并且实现了各种接口,这样的设计模式其实是值得学习和借鉴的。当然,在实际操作中可能会有很大难度,因为接口比之前灵活许多,可以继承,可以放变量等等,因此在定义接口时如何保持接口的单一性和扩展性是一个不小的考验。 - 善用泛型。很多时候 Swift 的 Generic 并不是显式的,类型推断帮助我们做了很多的事情,因此 Generic 这个概念可能被忽视的比较多。关于泛型这个强大的工具,因为原来 objc 中是没有的,而泛型的一个代表语言 C# 虽然平时有写,但很多时候只是当作类型安全的保证在用,我自己也没有太多心得。但是在日常开发中还是多思考和总结,相信会很有进步。
- 尽快养成符合 Swift 的语法和习惯,比如
if let,比如对常量习惯性地用let而不要用var,在上下文明确的时候省掉原来习惯写的self,枚举只使用.,合适地使用_这样的符号来增加可读性等等。既然写 Swift,就应该入乡随俗,尊重这门语言的规范,这样不管在之后和别人的讨论交流上,还是自我的长期发展上,都会很有帮助。 - 安心等 Apple 进一步完善。现在 Swift 还处在相对很早期的阶段,很多东西虽然已经基本定型了,但是也有不少可塑性。编译器和调试器现在感觉还不太好用(当然,因为还在 beta,也不是说责怪什么),而且对于原来基于 objc 写的 Cocoa 框架还是有很多水土不服的地方。我个人来说,现在的水平使用 Swift 写还凑合 app 这样的级别应该问题不大,在这篇文章之后我暂时不会再进一步深挖 Swift,而是打算等待正式版出来之后再看情况使用。现在 Swift 仅在
String上可以和 Cocoa 框架完美对接,而对于像Array这样的类型,虽然通过一些巧妙的方式完成了桥接,但是在实际使用上可能还是需要借助大量的NSArray,在转换上略显麻烦。按照现在来看,Apple 应该至少会将 Cocoa 框架另外几个重要的类迅速适配 Swift 的语言习惯,如果能找到 一种很方便地使用 Cocoa 框架的方法的话,objc 程序员转型 Swift 就应该相对容易一些了。
洋洋洒洒不小心写了这么多(其实我还删了两节..因为写不动了),希望能对您学习和深入了解 Swift 有所帮助吧。因为很晚了,我没有仔细校对,文中肯定有不少错误(技术上和文字上的),欢迎您指出,我会尽快改正。