WWDC 2025 上,苹果公布了设备端的 Foundation Models 框架,可以让开发者们使用离线模型完成一些基本的 AI 任务。虽然各个 session 已经详细介绍了基本用法,但作为开发者,我们更关心的往往是:这个框架的边界在哪里?什么情况下会出现问题?实际性能如何?
经过近一周的测试和探索,我有了一些有趣的发现。这些发现可能对你在实际项目中使用 Foundation Models 有所帮助。
重要提醒:本文所有结论基于 macOS/iOS/Xcode 26 Beta 1,实际发布版本可能会有变化。苹果在 lab 中也明确表示,模型会随着 iOS 版本更新而持续改进。
结论先行
Foundation Models 已经可以用于生产环境了吗? 我的答案是比较乐观:虽然还是 beta 1,但框架的稳定性出人意料地好。Apple 一改往年 beta 约等于 alpha 的特性,这次端出了大体能用的东西,让人喜出望外。不过,你还是需要了解它的边界和限制。
核心发现汇总:
- 内存消耗:总运行时内存约 1.0-1.5GB(模型权重 750MB + KV cache + 框架开销)
- 上下文窗口:实际限制为 4096 tokens,不是训练时的 65K
- 并发性能:多 session 并发会严重影响性能,从 10-30 tokens/s 降至约 1 token/s
- Schema 开销:每个 @Generable 属性约增加 30 tokens 开销
- 温度敏感性:意外地不敏感,0.0-2.0 范围内表现稳定
- 安全防护:相当严格,会删除违规的 transcript 条目
性能特征:数字背后的真相
内存使用:不只是模型权重
苹果宣传的是 3B 参数、2-bit 量化的模型,按理说模型权重约 750MB。但实际运行时的内存占用要大得多:
1
2
3
4
5
模型权重: ~750MB (3B params × 2-bit)
KV Cache: ~300-600MB (8-bit 量化, 37.5% 减少优化)
框架开销: ~100-200MB
────────────────────────────────────
总计: ~1.0-1.5GB
这意味着在内存受限的设备上,你需要仔细考虑何时加载和释放 session。好消息是苹果做了很多优化,比如 KV cache 的 8-bit 量化和 37.5% 的 block sharing 减少;而 base 模型本身似乎在不用时也会自动 unload。
上下文窗口:训练 vs 部署的差异
这里有个容易被误解的地方。苹果提到模型训练时支持最高 65K tokens 的上下文,但实际部署到用户设备上时,硬限制是 4096 tokens。
1
2
3
4
// 超出上下文窗口时会抛出这个错误
catch LanguageModelSession.GenerationError.exceededContextWindowSize {
// 需要总结对话历史,重新开始 session
}
对于一般的对话场景,4096 tokens 大约能支持 10-20 轮对话。但如果你的 instructions 很长,或者需要处理大量上下文,就需要提前设计好上下文管理策略。
并发性能:单 session 为王
测试中最意外的发现之一是多 session 并发的性能下降。
单 session 性能:
- iPhone:约 10-30 tokens/s
- M2 Pro:约 30 tokens/s
3 个并发 session:
- 所有设备:每个 session 的性能都骤降到约 1 token/s
显然,苹果只考虑了单 session 的使用场景。如果你的应用需要处理多个并发的 AI 任务,建议全局管理一个 session,使用队列去串行访问,避免任何并发 session。
1
2
3
4
5
6
7
8
9
// 推荐:使用队列管理请求
actor SessionManager {
private let session = LanguageModelSession()
private var requestQueue: [AIRequest] = []
func processRequest(_ request: AIRequest) async -> AIResponse {
// 串行处理,不要并发
}
}
当然,不排除这只是 beta 阶段的 bug,或者 Apple 未来会在底层帮我们实现一个串行队列的使用方式。否则,多 session 并行导致的性能瞬间恶化,还是相当出乎意料的。
Guided Generation:Schema 的代价
@Generable 宏是 Foundation Models 的亮点之一,但要注意它并非完全 free。保持简短的属性名和描述时,每个 @Generable 属性依然大约会增加 30 tokens 的 schema 开销。一些 Input Prompt token 数的实测数据(同样的 prompt,逐个增加 Generable 的属性数量):
1
2
3
4
5
1 属性: 313 tokens
2 属性: 345 tokens
3 属性: 374 tokens
4 属性: 417 tokens
5 属性: 442 tokens
单个属性开销不大,但累加起来并不断发送的话,在 4k 这个上下文窗口限制下还是不容小觑。特别对于复杂的数据结构,这些开销可能会快速消耗你的上下文窗口。
includeSchemaInPrompt 优化
苹果提供了一个优化选项 includeSchemaInPrompt: false,理论上可以减少 input tokens。但在测试中发现,这个选项在 beta 1 中没有按预期工作。
1
2
3
4
5
6
// 在 beta 1 中,这样的调用完全没有减少 input prompt
let response = try await session.respond(
to: prompt,
generating: MyType.self,
includeSchemaInPrompt: false // 可能不会显著减少 tokens
)
这可能是因为底层的约束解码(constrained decoding)机制仍需要完整的 schema 信息,即使不在 prompt 文本中显示。不过也有可能是 beta 1 的 bug。
Bug Reported: FB17935029
Tool Calling:隐藏的宝石
虽然 WWDC session 中对 Tool Calling 的介绍相对简短,但我认为这是 Foundation Models 最有价值的功能之一。它在概念上与 Model Context Protocol (MCP) 相似,但具有 Swift 的类型安全优势。
Tool Calling 让用户能通过自然语言控制应用功能,这可能是”工具导向编程”时代的开始。
温度与创造力:意外的发现
在创造性任务测试中,我发现 Foundation Models 对温度参数的敏感性比预期要低:
- 0.0-0.7:输出几乎相同,遵循指令
- 0.7-1.5:逐渐增加创造性,但仍然可控(默认 0.7)
- 1.5-2.0:最大创造性,偶尔会有意外惊喜
这与一些其他温度相对敏感的模型的表现有明显差异,在整个支持范围里,模型对于指令的跟随都还不错。
对于需要创造性输出的场景,适当调高温度到 1.5 左右会有更好的结果。
当使用大于 2.0 的温度时,系统会给出运行时的警告。
安全防护:严格但有副作用
苹果的安全防护相当严格,但有一个值得注意的行为:当触发安全防护时,transcript 中违规的条目会被完全删除。
1
2
3
4
5
// 防护触发前
session.transcript.entries.count // → 10
// 防护触发后
session.transcript.entries.count // → 9 (违规条目被删除)
这意味着你很难调试安全防护的触发原因。建议在开发阶段保留一份对话日志,以便分析和改进。 当然,重点还是调试更好的 instruction 和 prompt,以及合理的错误处理机制。
开发中的坑和解决方案
问题 1:Playground 支持问题
虽然 Session 里所有人都在尝试教你使用 Playground 调试 Prompt,但 beta 1 里在独立的 Swift Playground 中无法直接使用 Foundation Models:
1
2
3
4
5
6
7
8
9
import FoundationModels
import Playgrounds
#Playground {
// ❌ 在独立 Playground 中会失败
// Couldn't look up symbols: Playgrounds.init(...
let session = LanguageModelSession()
// ...
}
解决方案:在 Xcode 项目内创建 Playground,或直接在项目中测试。目测后续版本大概率会修复这个问题(看起来修复会比较容易,赚 KPI 嘛,不寒碜)。
Bug Reported: FB17969152
问题 2:语言检测误报
有时候长文本(80+ 字符)会触发”不支持的语言”错误,即使内容是支持的语言。
实测中一些很正常的文本,比如把这个放到 prompt 中:
1
2
3
4
5
6
7
我在开发一个quiz的游戏app,现在有个统计界面,需要显示如下数据:
- 完成挑战天数
- 最高连续正确
- 完成挑战次数
我现在需要把这三项翻译成英文,帮我挑选合适的词句。因为要显示在手机屏幕UI上,不能太长,但是也还是要保持清晰
beta 1 中稳定触发错误:
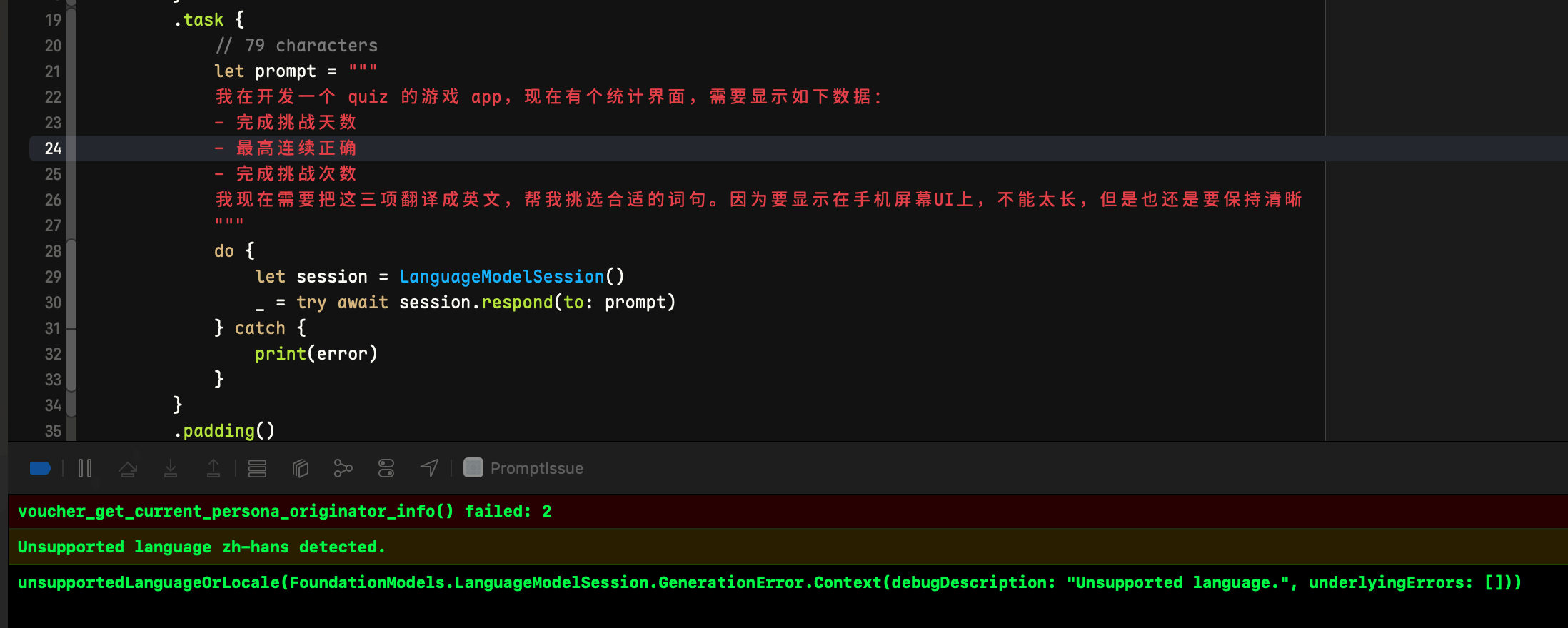
看起来是语言识别为了 zh-Hans (这是正确的),但是 SystemLanguageModel.default.supportedLanguages 列表里定义的是 zh-CN。 但是奇怪的是,不在支持列表里繁体中文的 zh-Hant 或者 zh-TW 却又能工作,没搞太懂。但是应该不是很难修。
其他还有一些例子,不再展示了。
临时解决方案:
- 缩短输入文本
- 在 prompt 中明确指定语言
Bug Reported: FB17874349
问题 3:工具调用不太稳定
1
2
3
4
5
6
7
8
9
// 根据提示词的细微差别,有时候会调用,但有时候又不会
let session = LanguageModelSession(
tools: [WeatherTool()]
)
let response = try await session.respond(
to: "What's the weather like in Tokyo?"
)
// Response: I don't have the weather information for Tokyo right now.
虽然从人类的角度来看提示词已经很明确,但是根据某些难以察觉的细微不同,有时候工具调用不太稳定, 这应该还是模型性能的限制,估计没有太多办法。如果你确定某个工具调用应该优先,可以尝试在提示词中 明确进行指示,来辅助模型做出调用工具的决策。
Bug Reported: FB17964201
一些体会和思考
Foundation Models 给我最大的感受是:这是一个为了实用而设计的框架,而不是为了炫技。3B 参数在当今的大模型时代看起来不大,但苹果针对设备端的场景做了大量优化:
- 2-bit 量化:保持了模型质量的同时大幅减少了存储和内存需求
- 推测解码和草稿模型:在 3B 模型外,还搭配了一个 300M 的 draft model,提升了推理速度
- 约束解码:确保了结构化输出的可靠性
- Tool Calling:为应用集成提供了优雅的解决方案
不过,也要认识到它的限制:
- 世界知识有限(训练数据截止到 2023 年 10 月,美国总统还是拜登!)
- 不适合数学计算和代码生成
- 复杂推理能力有限
但对于文本摘要、内容分类、结构化数据提取这些任务,它的表现相当不错。
未来展望
苹果明确表示模型会随着系统更新持续改进,这意味着你针对旧版本模型调好的 prompt 可能会在新版本模型上不太适用。Apple 建议 我们设定 test set,在每次模型更新时进行确认和调整。考虑到模型的更新间隔大概是半年到一年,因此每年可能会有两个新版本模型 需要确认,这也是一定工作量。
如果模型变化很大,导致无法同时针对新旧模型寻找到同样好的 prompt,我们可能甚至需要针对不同的系统版本使用不同的提示词,这 也会带来额外的维护开销,值得注意。
另外,macOS 上搭载的本地模型也是这个 3B 的小模型(同时也提供给 macOS 26 上的模拟器使用),这让人有一些失望:作为性能 更加强劲的“生产力级别”设备,却使用了和手持设备一样的方案。希望今后能看到 macOS 上有更强力,至少是上下文窗口更大的模型, 并发挥出隐私优先和本地运行的优势吧。
给开发者的建议
如果你正在考虑在项目中使用 Foundation Models:
- 现在就可以开始实验,框架已经相当稳定
- 围绕 4096 token 限制设计应用流程,不要指望短期内会有大幅提升
- 优先考虑 Tool Calling,这可能是最有价值的功能
- 准备好上下文管理策略,如果存在对话式的场景,几乎必须处理上下文溢出
- 在真机上测试性能,模拟器版本跑的是 macOS 搭载的模型,性能结果可能不准确
Foundation Models 不是万能的,但它为 iOS 应用带来了前所未有的 AI 能力。关键是理解它的边界,并在这些边界内发挥创造力。
参考资料:
- Meet the Foundation Models framework - WWDC25
- Deep dive into the Foundation Models framework - WWDC25
- Code-along: Bring on-device AI to your app using Foundation Models - WWDC25
- Explore prompt design & safety for on-device foundation models - WWDC25
再次强调,本文基于 macOS/iOS/Xcode 26 Beta 1 的测试结果,后续版本可能会有所不同。如果你有不同的发现或问题,欢迎讨论。